
一.背景
网络抓包技术在定位现代复杂的网络问题中有着举足轻重的作用。tcpdump,wireshark这些抓包工具成为运维,研发人员定位网络问题的瑞士军刀。不管你是什么样的应用,采用什么样的网络协议,最终都是一个个符合某种协议规范的报文在网络上传输,只要我们抓住这些报文加以分析,一般都能找到网络问题的根源。
但是,随着7层网络负载均衡器(后文简称LB)的引入,从客户端到服务器的请求从一个TCP连接变成了两个独立的TCP连接:从客户端到LB的连接从LB到服务器的连接
两个连接共同完成从客户端到服务器端的请求和应答。如果要想知道从客户端到服务器整个链路上的网络传输情况,我们势必要把这两条连接上的报文都给抓出来。不仅如此,我们还要知道这两条不同连接上的报文的对应关系。这里有两个主要的问题需要解决:
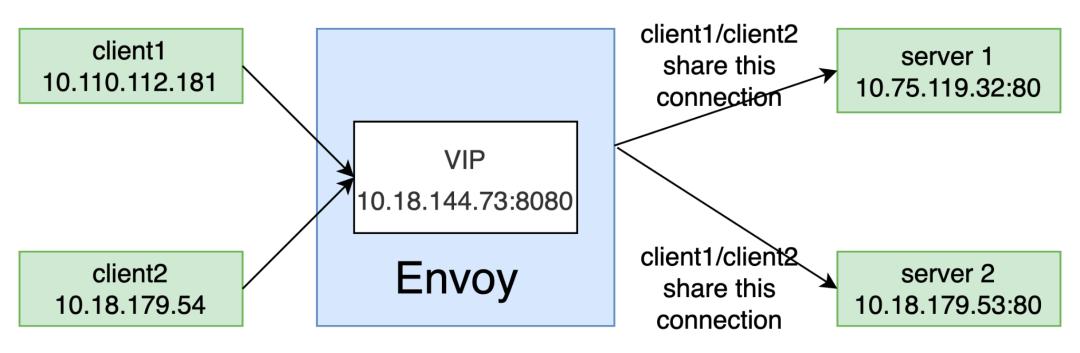

(点击可查看大图)
对于客户端到LB的一个HTTP请求,LB在把这个请求转给后端服务器的时候有多个服务器可以选择(如上图所示有server1,server2)。当LB选好某一个服务器之后,还需要从同一个服务器中的多个tcp连接中选择一个连接来传输报文。以上图为例,我们已经知道CLIent和VIP的地址和端口信息,根据这些过滤条件,我们很容易抓取到客户端到LB到报文。但是,我们并不知道LB会选择哪一个后端服务器的哪一个TCP连接来转发这个请求,也就没办法加入过滤条件来抓取后端的报文。? ? ? ? ? ? ? ?
对于多个客户端到LB的HTTP请求,如果是先后发生的,那么LB一般会复用同一个从LB到服务器的TCP连接来处理这些请求。这意味着我们从LB到服务器的抓包中,并没有办法确定这些报文是来自于哪一个客户端到LB的哪一个连接。这使得我们在排查问题的时候没有办法形成一个从客户端到LB,再从LB到服务器的完整的链路分析。? ? ? ? ? ? ? ?
从上面的图中可以看到,client1和client2同时都去访问同一个VIP,此时LB一般情况下并不会和后端同一个服务器建立两条TCP连接来分别处理client1和client2的请求。LB会复用同一条到后端服务器的连接来处理client1和client2的请求。这样我们就算抓到从LB到后端服务器的报文,我们也无法判断这个报文是在处理client1的请求还是client2的请求。
二.问题分析
在eBay之前的网络架构中,主要使用厂商提供的硬件负载均衡器(后文简称HLB)。厂商都提供了丰富的网络排查工具帮助我们定位问题,比如netscaler的nstrace。为什么nstrace能解决前面提到的问题呢?
这是因为,厂商的LB接管了报文的整个生命周期。也就是从接收到报文开始,经过处理,到最后发出去报文,整个过程都是在LB的控制范围内。所以HLB有能力知道报文转发的时候的两个关键信息:报文发给了哪一个后端服务器选用了跟后端服务器之间的哪一条TCP连接来发包
同时,nstrace抓包的介入点也是厂商的软件可以自己完全控制的,可以在报文处理的任何一个时刻去抓包。从下图中可以看到,HLB可以在刚接收到报文的时候抓包,也可以在LB处理完客户端连接并创建和服务器端连接的时候抓包,也可以在报文完全组装好,准备发给服务器的时候抓包,所以它要解决前面两个问题相对来说是容易的。
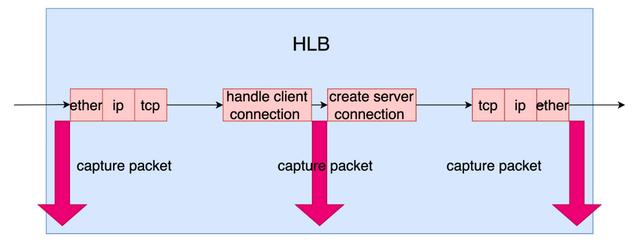
(点击可查看大图)
目前eBay内部的网络架构中,以软件实现的负载均衡器(后文简称SLB)已经开始大规模替换HLB。eBay的SLB选用了目前业界流行的envoy。Envoy是一个运行于操作系统(本文中讲述的内容只针对Linux)之上的应用软件,它基于操作系统提供的socket API来完成报文的接收和转发。作为应用软件,envoy通过socket收发的是应用层协议的数据,而完整的TCP/IP报文却是Linux内核的网络协议栈来负责的。这跟HLB有着很大的不同。我们通常的抓包工具抓包的时间点是在内核协议栈里,而且这个时间点也是固定的。从下面的图中我们可以看到在收包(ingress packet capture)和发包(egress packet capture)的时候抓包的位置。抓包是发生在网络驱动程序和以太报文处理之间。
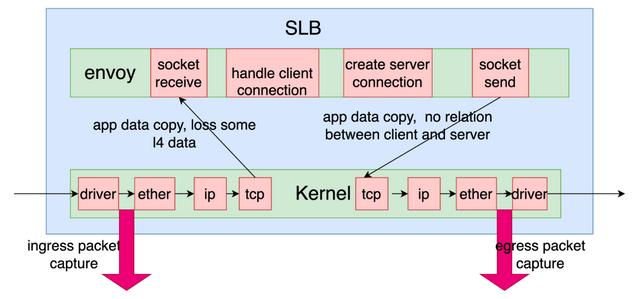
(点击可查看大图)
对于本文的情况,我们只知道客户端地址端口和VIP的地址端口,这可以帮助我们抓到客户端到LB的报文。然而,对于LB到服务器这条连接,我们并不知道报文的目的地址,抓包的时候没有足够的信息可以帮助我们过滤得到我们想要的报文。
三.解决方案
本文设计并实现了一套工具,能够根据客户端IP地址和要访问的虚拟IP地址和端口(VIP),抓取从客户和LB之间以及对应的从LB和服务器之间交互的所有报文,从而形成完整的链路来分析网络问题。本文的讨论都是基于TCP协议上运行HTTP/HTTPS的场景。
我们先来看一下envoy和内核各自持有哪些信息:Envoy:唯一知道报文应该发送给哪个服务器的哪一条连接的组件。内核:只是负责按照envoy的指示把应用层的数据封装各层网络协议报头之后发送到网络上。所以我们首先需要改造的就是envoy本身的源代码,让它能够在把应用层数据传递给内核的时候(向后端服务器发送报文时)携带更多的信息,让内核能够清楚知道这个报文是来自于哪个客户端的哪个TCP连接。好在envoy来自于开源社区,我们能够比较方便地去修改源代码满足我们的需求。内核接收到envoy传递过来的有关客户端的信息之后,首先需要将该信息保存到报文的内核数据结构skb里面。现在内核有了这些信息,那么内核还需要哪些改动才能将这些信息不断传递下去,直到我们抓包的时候也能够获取到这些信息呢?有以下几种方法可以选择:
通过eBPF方式加入自己的代码逻辑插入到内核中。但是对于我们需要修改的TCP发包函数并没有hook点可以插入,对于eBPF trace/kprobe的方式虽然可以找到TCP发包函数,但是eBPF trace/kprobe 对于内核数据都是只读的,无法进行数据的改写。所以此方法其实是不可行的。直接修改内核,重新编译。出于对eBay当前实际情况的考量,此方法成本较高,不易推行。以动态加载模块的方式去改变内核行为。理论上这是大多数时候增加内核功能的推荐方式。这种方法其实又可以分为两种情况:内核已经提供了动态加载的Hook点。本文的情况是需要修改TCP发包函数,这个并没有直接相关的Hook点,除非我们替换整个TCP模块。但是我们需要的代码修改量其实非常少,完全没有必要替换整个TCP模块。利用livepatch的方式去替换内核的一些函数。
最终我们选择了livepatch的方式去更改内核代码,将数据保存到skb中。通过livepatch的方式还可以达到按需加载的目的,因为绝大多数时候是不需要这个patch的,只有我们需要排查问题的时候才加载,任务完成之后就可以卸载patch了。这样对系统的影响也是最小的。当前内核基于传统cBPF抓包的时候,内核里的cBPF程序只能根据报文本身的内容做过滤,也就是根据数据链路层、IP层、传输层、应用层(基于报文数据偏移量来实现)报头来过滤,cBPF并不具有解析协议本身的能力。如果我们希望的过滤条件不是报文上固定的偏移量或者这个过滤条件本身就不属于报文的某个字段,cBPF就无能为力了。比如我们用tcpdump做抓包的时候,常用的过滤条件,比如IP地址、端口、TCP flag等等,都属于RFC规定的在报文固定位置出现的字段。另外一些属性,比如这个报文是属于哪个应用进程,这种信息是无法在报文上面体现的,也就不能作为抓包过滤条件。为了达到根据envoy传递给内核的信息进行过滤的目的,我们有几种可选办法:
不改动报文长度,将信息写入某层协议报头的某个已知字段。此方法需要找到一些RFC定义的保留字段或者更改已知字段的值,具有一定风险。

(点击可查看大图)
改动报文长度,将信息以字段选项的形式插入到当前报文,比如IP option或者TCP option。此方法需要增加报文长度,会带来额外附载。

(点击可查看大图)
改造当前cBPF的实现,让cBPF能够通过skb的一些字段对报文进行过滤,而不是仅仅通过报文自身的字段来进行过滤。此方法要求对于cBPF有足够的了解,但是cBPF本身代码晦涩难懂,不易操作。而且对于内核的影响也是难以估计。

(点击可查看大图)
以eBPF的方式,插入一段代码并设置过滤条件,将报文从内核直接发送到用户空间。因为可以加入自定义代码,所以过滤条件可以十分灵活,除了可以根据报文本身任意字段外,还可以根据报文对应的skb上所有的元数据以及状态信息进行过滤。
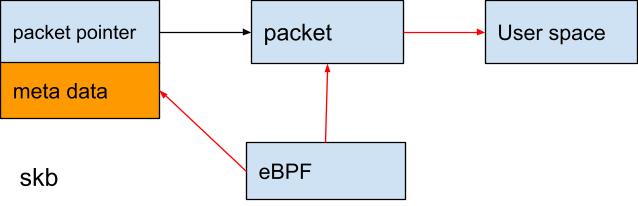
(点击可查看大图)
上面的方法中,第4种看上去是最完美的方式,也是笔者一开始去实际操作的方法。在Linux Kernel 5.5 开始引入了新的helper 函数 bpf_skb_output, 可以将报文以BPF perf event的方式从内核态发送到用户态空间。
int bpf_skb_output(void *ctx, struct bpf_map *map, u64 flags, void *data, u64 size)+ * Description+ * Write raw *data* blob into a special BPF perf event held by+ * *map* of type **BPF_MAP_TYPE_PERF_EVENT_ARRAY**.
在实际编写代码测试的时候发现,当流量达到5MB/s左右的时候就已经开始出现event丢失的情况了。 通过查看这个helper函数的实现,可以发现是通过内存拷贝的方式将整个报文复制一份。虽然报文拷贝确实是性能的大敌,但是在5M/s这么低的流量就开始丢失event是不能用内存拷贝来解释的。我们发现,最大的问题还是在于BPF的perf event本身的机制。简单的说就是用户程序通过定期轮询的方式去从内核获取event。不管我们把这个轮询的时间间隔设置多短,最后设置成没有间隔的不断轮询,性能上并没有太大的提升,不超过10MB就开始丢event了。除了性能的原因,当前eBay生产环境上使用的kernel版本还是5.4,就算采用这个方法,还需要升级内核版本或者把eBPF相关的patch引入到当前版本,这些工作都不在控制范围之内。所以最终没有进一步去研究如何提升BPF perf event的性能来达到抓包的目的,但是我觉得这是eBPF可以去改进的地方。
最终我们在项目中选择了第二种方法。该方法是在Linux默认提供的netfilter框架里加入我们自己的代码去插入新的TCP Option报头选项。后面会详细描述如何去实现的。
通过这种方法,我们成功地将客户端到LB的连接信息传递到了从LB发送给服务器的报文之中,cBPF根据这些信息来进行过滤就成为了可能!
不过我们也不能高兴的太早。现在虽然解决了从LB到服务器的请求报文中携带客户端相关信息的问题,这个客户端信息被保存在TCP option里,但是从后端服务器返回给LB的报文中是没有这个TCP option的。所以我们还需要一种机制能抓取从服务器返回给LB的报文。
这里要强调的是:我们在抓取报文的时候已知条件只有客户端地址和VIP地址,对于后端服务器的IP端口信息,我们是一无所知的。因此在通过TCP option作为filter抓到LB到服务器的报文的时候,还得把这个包含TCP option的报文的源目的IP地址和源目的端口四元组记录下来,用来过滤从服务器返回给LB的报文。这里我们选择了eBPF trace的方式,把这个四元组通过eBPF event暴露给用户态的抓包程序,然后抓包程序根据这个四元组动态启动抓包线程去抓取服务器到LB的报文。
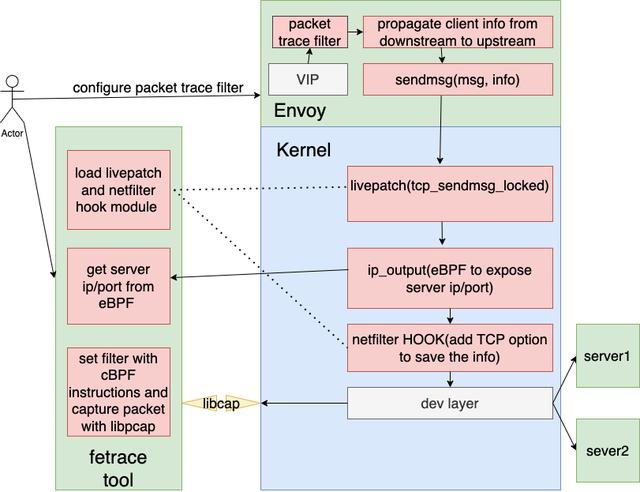
(点击可查看大图)
从上面的框架图中,我把整个工具链分成三部分:
fetrace tool这是一个用户真正操作的命令行工具集。它主要完成下面的功能:根据需求动态加载/卸载 livepatch 模块和netfilter hook模块。获取eBPF trace程序的结果(服务器IP和端口),动态启动一个线程去过滤并捕获LB和这个服务器之间的我们期望的报文。把用户输入的过滤条件(基于tcpdump语法)转化成内核可识别的cBPF代码,然后调用libpcap去过滤并捕获报文。
envoy
加入新的network filter来配置你想要抓取报文的的客户端IP/端口和VIP信息。通过envoy的dynamic metadata机制将客户端信息传递给LB发给后端服务器的连接。替换envoy的发包函数,把客户端信息传递到内核中。
内核
livepatch:从envoy传递过来的数据中解析出客户端信息并保存到skb。eBPF trace (ip_output): 将服务器IP和端口信息暴露给用户态的fetrace tool。etfilter hook:将客户端信息插入到TCP报头选项。
Envoy
Packet Trace Filterenvoy提供了filter的插件编写,本文加入了一个新的filter作为packet trace的过滤条件。
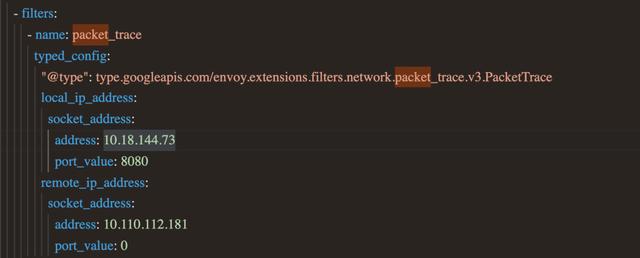
(点击可查看大图)
通过上面这个filter,envoy就会抓取满足以下条件的报文:
- 目的IP是10.18.144.73
- 目的端口是8080
- 源IP是10.110.112.181
在实际情况中, 客户端端口一般是系统随机分配的,所以一般无法也不需要指定这个值。通过上面的配置,envoy只对满足这三个过滤条件的客户端到LB的TCP连接做抓包,同时抓取对应的从LB到后端服务器的TCP连接报文。客户端信息的传递Envoy提供了filter dynamic metadata机制。本文增加了dynamic metadata从下游连接(客户端到LB)传递到上游连接(LB到服务器)的功能。这样客户端信息被当成一种dynamic metadata, 传递到LB和服务器端的连接里。关于这部分的实现,起初笔者是直接将envoy的上游和下游连接加入指针互指来完成,后来在envoy核心开发维护者的建议下采用了目前的方案。因为从envoy的设计来说,上下游的连接是解耦的,不应该直接把上下游的连接直接关联,否则就违背了envoy的设计初衷。发包
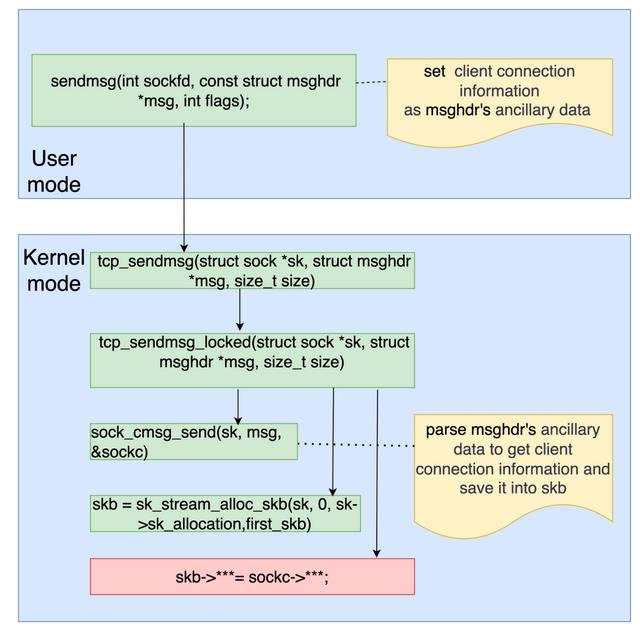
(点击可查看大图)
通过上面的图,我们可以看到对于envoy发包的改动就是在调用socket API的时候,把客户端端口信息加入到TCP socket的ancillary data里去。因为有了前面packet trace filter的过滤,这里envoy只需要针对满足过滤条件的报文加入额外的信息。因为packet trace filter 过滤条件里已经包含了客户端IP信息,所以这里我们只需要将客户端的端口信息加入到TCP socket的ancillary data就足够了。
Kernel
Livepatch
结合前面envoy发包的图中,内核部分需要修改tcp_sendmsg_locked函数,将从socket ancillary data取出客户端的端口信息并保存到skb某个字段。我们选用了一个eBay内部没有使用到的一个字段来保存这个值。
Netfilter Hook
我们选择用netfilter hook插入skb里保存的客户端的端口信息,是应该把这个值插入到IP option ,还是TCP option呢?考虑到我们的netfilter hook是在IP层的hook,一开始本文选择将这个值插入到IP option。但是在做性能测试的时候却发现,该方法对网络延时有非常大的影响。我们先来看一下报文的完整流程:
客户端发起请求 -> LB处理 -> 服务器处理 -> 服务器回复请求 -> LB处理 -> 客户端
整个过程在我的测试环境中,不插入IP option的时候只需要几毫秒,插入IP option并且不引起IP分片的情况下,延迟可以高达100毫秒。从我们netfilter hook加入的代码分析,虽然有内存拷贝来插入IP option的操作(通常情况下,该操作是影响性能的关键因素之一),但是在本文的情况下,内存拷贝的长度是很小的,就是IP报头的移动,只有二十个字节,理论上不应该对延迟有这么大的影响。但是经过多次测试,仍然是同样的结果。于是我们通过打时间戳的办法将报文的整个过程分成 netfilter hook之前、之后、内核驱动发送报文、服务器收到报文、服务器发出报文、LB收到回复报文这几个过程。最后对比发现,时间基本消耗在内核驱动发送报文到服务器收到报文阶段。由此也可看出,插入IP option引起的时延并不来自于内核的操作,而是来自于从LB到服务器中间的网络设备(交换机/路由器/防火墙)。由此推测网络设备对于自定义的IP option处理是比较低效的。但是我们又没法改变中间设备,于是选择TCP option的方法再次尝试,好在这次的结果是令人欣慰的:在使用自定义TCP option的情况下,延迟没有发生明显改变。
eBPF
由于本文只使用eBPF的trace功能,所以选择了当前比较成熟的BCC框架,从内核ip_output函数中导出服务器IP和端口信息。fetrace tool 用golang进行简单封装之后,通过eBPF event获取到服务器IP和端口。
CLI (fetrace tool)
包括了:基于kpatch的shell脚本,负责加载/卸载 livepatch和netfilter hook。基于golang的CLI,负责读取用户希望的过滤参数并根据eBPF导出的服务器IP和端口动态启动goroutine过滤抓取LB和某个服务器之间的报文。这里针对客户端到LB和LB到每个服务器分别启动一个goroutine。最终结束抓包后,CLI负责将所有单个抓包文件合并成一个文件。
四.演示
网络拓扑
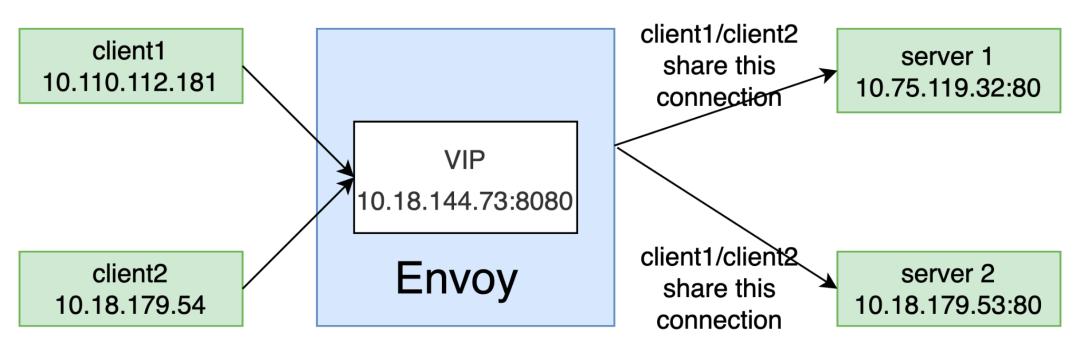
(点击可查看大图)
步骤
在本次演示过程中,envoy和fetrace以docker容器方式,以host network模式运行于内核5.4-59版本的Ubuntu操作系统的同一台虚拟机中。client1/2 server1/2 分别以docker容器方式,运行于不同的虚拟机之中。在fetrace 容器之中加载livepatch和netfilter模块
root@xxxx:/# ./fetrace/scripts/pre_start.sh loadStarting load live patchloading patch module: /fetrace/modules/livepatch-mark_patch_1-5.4.0-59.ko waiting (up to 15 seconds) for patch transition to complete…transition complete (1 seconds)
- 在envoy容器之中配置packet trace filter指定client IP,VIP IP和端口
在client1/2, server1/2 分别启动Envoy nighthawk测试工具收发http流量
client http://10.18.144.73:8080 –duration 30 –concurrency 10 –rps 100
- 在fetrace容器之中,启动CLI抓包报文,大约30秒之后,“Ctrl-c” 终止CLI
root@xxxx:/# ./fetrace/bin/fetrace –cif eth0 –vip 10.18.144.73 –vport 8080 –cip 10.110.112.181I0806 04:01:50.267638 37 main.go:140] Notify sub goroutine quitI0806 04:01:50.267683 37 pcap.go:190] V2S receives quitI0806 04:01:50.267694 37 pcap.go:190] V2S receives quitI0806 04:01:50.267733 37 pcap.go:188] C2V receives quitI0806 04:01:50.267755 37 main.go:129] C2V goroutine exitI0806 04:01:50.267640 37 capture.go:104] Perf stopI0806 04:01:50.586269 37 main.go:135] eBPF goroutine exitI0806 04:01:50.586288 37 main.go:143] Merge all pcapI0806 04:01:50.595461 37 main.go:145] Main thread exit
然后可以在fetrace容器里看到如下抓包文件
root@xxxx:/# ls *.pcapc2v.pcap final.pcap v2s_10.18.144.73_47842_10.75.119.32_80.pcap v2s_10.18.144.73_49990_10.75.119.32_80.pcap
c2v.pcap: clientvip
v2s_xxxx.pcap: 对应每一个服务器一个抓包文件
final.pcap: 所有抓包文件合并成一个
- 用wireshark打开final.pcap
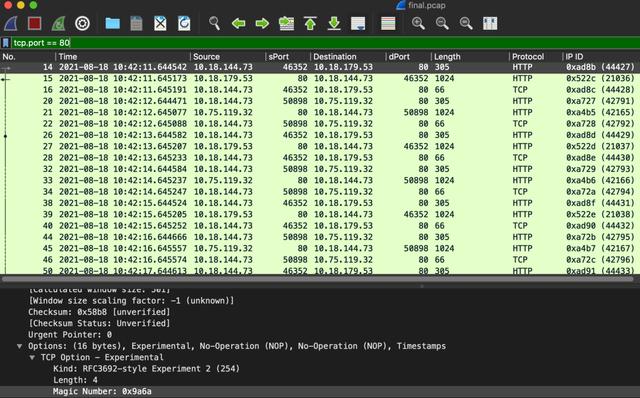
(点击可查看大图)
可以看到从LB到服务器的报文的TCP字段多了一个自定义的TCP option。这里的Magic Number 0x9a6a 转换成10进制(44350)之后就是客户端发起连接的端口号。通过这个端口号,我们就可以把从客户端发送给LB和LB发送到后端服务器的报文给对应起来了。
10.110.112.181:44350>10.18.144.73:8080->10.18.179.53:80
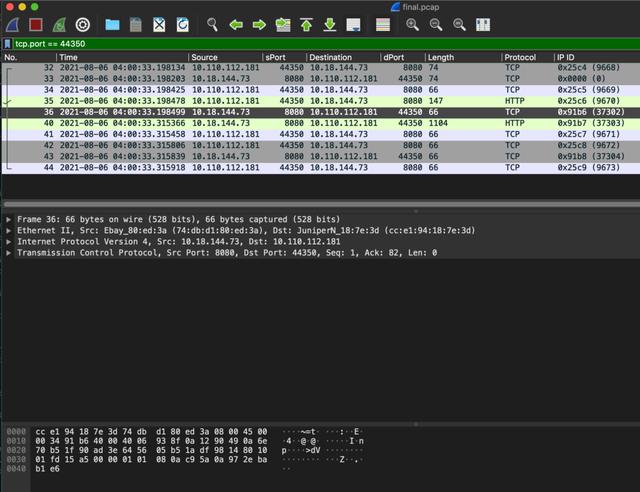
(点击可查看大图)
- 在fetrace容器中,抓包完成之后卸载模块
root@xxxx:/# ./fetrace/scripts/pre_start.sh unloadStarting unload live patchdisabling patch module: livepatch_mark_patchwaiting (up to 15 seconds) for patch transition to complete…transition complete (2 seconds)unloading patch module: livepatch_mark_patchUnload fetrace_hook module
五.总结和展望
在基于socket的网络应用软件中,网络中传输的报文经过内核协议栈处理之后,用户态程序接收到的信息并不能完全包含传输过程中的所有信息。对于大部分应用来说,用户态程序的确不需要知道底层的传输信息,这也正是socket设计之初衷,希望屏蔽和应用无关的底层信息,让应用开发者专注于业务层面的逻辑开发。但是,随着网络基础架构和应用架构的不断演化,信息传输已经不再是简单的客户端和服务器端的直接传输,中间过程会涉及多次处理,比如7层负载均衡的代理模式就需要终止当前传输,然后新建连接;比如微服务架构更是要求一个简单的请求需要经过多个服务器之间的中转才能最终完成一次请求和答复。因此,如何把所有这些中间过程的处理形成一条完整的、可追踪的全链路成了一个巨大的挑战。当前关于全链路追踪的解决方案都是从应用的层面在应用层去添加额外的追踪信息来实现,比如HTTP协议的X-Forwarded-For头部或者trace ID头部等机制。这些机制对于关心具体应用的开发者来说确实是有效的。但是从网络基础架构的层面来看,我们并不关心应用层的具体协议,那么就需要把追踪信息下沉到更低的网络协议层。
本文基于传输层的追踪信息做了相关研究并给出了可行性方案和实现。该解决方案从应用软件到内核都进行了相应的改进,从中我们可以看出当前基于socket的应用软件的一些弊端,即缺乏对于全链路需求的支持。为了让基于socket的软件能够更好的支持全链路追踪,我认为可以在以下几个方面进行增强:
从内核层面提供更加丰富的socket选项,让应用软件能够通过socket获取到任何可以在网络上传输的信息,比如各个网络协议层级的选项(ip选项,tcp选项,tls选项等等),同时也能让socket把更多的用户自定义属性从用户态传入到内核态,让协议栈能够自由地添加各个网络协议层级的选项来扩展网络传输的表达能力,从而获得到全链路的追踪能力。对应上面内核对socket的增强,提供增强的socket API(glibc)来适配。应用软件使用增强的socket API来进行编程。但是这对已有的软件有侵入性。对于源码不能修改或者源码修改的代价较大的情况,可以考虑采用用户态的ebpf hook来实现(需要进一步探索可行性和实际解决方案)。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/24450.html
相关推荐
-
w5500以太网模块(w5500以太网模块原理图)
设计的嵌入式PLC模块是一种被动响应的设备来进行研发设计的,本文嵌入式PLC模块自身不会主动向其他设备发起请求,仅仅会对以太网中发送过来支持三菱通信协议的数据包进行响应。 针对此特…
-
web安全工程师(web安全工程师证书)
相信很多人想进入网络安全,都是听说网络安全就业前景大,薪资很高,入门门槛也相对较低,但是,对于0-2年的网安新人,要学习网络安全往往还是存在以下方面困惑和迷茫。 没方向:网安种类千…
-
wap建站模板(wap网站模板)_
“ 做好网站的定位,是外贸企业搭建独立站的第一步。外贸网站的初期规划,决定了一个网站未来运营效果的好坏,更是决定了你的网站内容能否足够专业地表现公司的业务和产品。这里你需要确定“一…
-
轻量应用服务器装win7(服务器能装win7)
导读 前面两天咱们说了组装一台电脑如何选择电脑配件,在配件选择完成之后如何把这些电脑配件全部安装起来,这些工作全部完成之后,最后一步就是要给电脑装一个操作系统了,毕竟电脑没有操作系…
-
随意论坛怎么下载(随意社区怎么进不去)
三年的疫情反复,磨掉了多少人的意志,我们需要努力去增加,自己能就拥有了躺平的能力。很多人觉得你很努力,但其实只有你自己才知道到底在做什么! ?选择什么样的生活,喜欢什么不喜欢什么;…
-
保定疫情最新情况什么时候解封(保定疫情最新情况风险等级)
原创作者:石寿贵 跳鼓。苗语叫做“读拢”,本是附着在苗家椎牛仪式中的一个流程,是该仪式中的高潮和亮点。后来,由于广大社会群众对于文化娱乐的需要,人们将“读拢”(跳鼓)单独地从椎牛仪…
-
买空间(买空间网)
LOFT公寓自诞生以来,就备受国内年轻一代的青睐,因为复式的天然属性,天生就具备可供彰显个性的发挥空间,一层和二层加在一起让实际可用面积大为可观,能兼容居住、商业、文化、休闲等多种…
-
厦门做网站价格(厦门网络公司网站开发)_
导读:每个企业都需要建设网站,如何选择一家正确的公司?如何避免被坑?厦门公司网站建设哪家好?接下来由池塘厦门公司网站建设公司来给我们分享一下经验 厦门企业为什么要建设网站 企业网站…
-
云电脑一般多少钱(云电脑要多少钱)
中兴云电脑W100D 疫情以来,居家办公让人们对于电脑的需求持续走高。据Canalys数据显示,2021年全球PC电脑出货量总数约为3.41亿台,同比2020年增长15%。 对于企…
-
wan口速率设置(wan口速率设置选哪个速度快)
第六期粗略涉及软路由关于VLAN扩展的设置,本期将从PCDN的角度详细描述高恪软路由的安装和设置。如果还没看过前几期,请移步: PCDN躺赚项目详谈系列一前期准备 PCDN躺赚项目…