
1. 好久没理论创新了
任何互联网产品如果不能对外持续提供稳定服务,必将损失用户信心、口碑和商业利益。为了保障产品可用性和系统稳定性,产品的技术团队会不遗余力地做两件事:
- “improving availability”:提升系统稳定性,如优化代码和系统架构,力求提供高质量的代码制品和高性能高可用的运行环境;
- “quantifying availability”:量化系统稳定性,如统计成功率、请求延迟等指标,力求能一目了然地回答“我的产品挂了没有”、“一个月挂多久”等问题,也方便对外做出商业化sla承诺“请您放心,我的产品一个月最多只挂这么久!”(尤其付费云服务)

第一块improving工作大家讨论得很多,也做了很多事,今天我们重点讨论第二块quantifying。对于量化产品可用性,业界有很多成熟方法论:
- 基于数量的Success-Ratio
- 基于目标的Error-Budget
- 基于故障时间的MTTR/MTTF
- 基于规则阈值的SLA/SLO
- 基于状态的Uptime/Downtime
- ……
只需对系统数据实施采集、计算分析、可视化展示和异常报警,对绝大多数互联网产品而言,这便足够了。
但是,上述这些指标真的就够了吗?当一个大型产品的用户场景足够复杂,维护团队会不会在止血完一次线上事故之后,望着眼前绿色的请求成功率曲线图,心中嘀咕一句“怎么请求成功率还是那么高,根本就体现不出有一批用户登录失败”,旋即埋头回到这次事故的善后和复盘工作去了。
对于量化产品可用性这块工作,罕见有团队去创新理论。本文将回顾一下以前常用的量化指标的原理及其优缺点,并分享Google G Suite团队(负责Gmail邮箱服务、Drive云存储服务、Chat及时聊天服务、Calendar日历服务、Doc在线文档服务、等产品,后改名叫Google Workspace团队)的一次全新探索,他们提出了一个新指标叫User-Uptime(及其派生出的windowed User-Uptime)。
致力于系统稳定性建设的童鞋,强烈推荐阅读这篇Google paper原文《Meaningful Availability》(链接地址见文章结尾“参考资料”段落)。
2. 经典的量化指标
先简单回顾和总结一下这些常用指标的原理和优缺点。
2.1 请求成功率Success-Ratio
- 定义:
- 指一段时间内(如一天、一周、一个月)成功请求的数量除以全部请求总数量,success-ratio=successful request count÷total request count。是失败率的反义。
- 优点:
- 原理简单,说服力强,易统计。
- 缺点:
- 二义性。产品在同一时间统计到的请求成功率只有一个结果(如98%),但不同人却会有不同的感知和解读。典型情况就是高频请求用户和普通用户,前者发出98个请求失败了1个,后者可能发出了1个请求就失败了1个(对他们来说失败率是100%)。而对系统整体而言,收到了100个请求失败了2个,成功率计算结果确实是98%无误。
- 结果虚高。一类用户在发现产品故障后会选择离开一会(不想坐在那里不停重试),失败请求的数量少下去,公式计算出来的成功率百分比会偏高(分子不变,分母变小,商变大),无法准确反映对用户的影响程度。
2.2 系统故障率Incident-Ratio
- 定义:
- 指一段时间内系统正常时间除以总时间,incident-ratio=up minutes÷total minutes。“up”和“down”取决于系统已知的线上系统故障。
- 优点:
- 直观,说服力中等。
- 缺点:
- 二义性。何谓up何谓down,需要去定义,则存在人为操作和解释的空间。
- 不适用于大型分布式系统。对现代化的大规模系统而言,几乎不存在绝对的down和绝对的up,微服务拆分、多实例部署、主从热备、异地多活等手段令得整个网站很难彻底挂,而可能只是商品评论按钮点击没反应、购物车列表加载不出来、广东某市访问变慢、之类的“局部”异常。
2.3 故障恢复时间MTTF/MTTR
- 定义:
- MTTF(Mean Time To Failure,平均失效前时间)指系统可无故障运行的平均时间(或者工作次数),越高表示系统持续服务能力越强;
- MTTR(Mean Time To Recovery,平均故障恢复前时间)指从出现故障到修复故障之间的时长(包含了确认失效和排查故障源头等所需的时间),越短表示系统易恢复性越好;
- MTBF(Mean Time Between Failures,平均故障间隔时间)指两次相邻故障之间的时长,MTBF=MTTF+MTTR。通常MTTR远小于MTTF,因此MTBF≈MTTF;
- 此外,还有MTTD(D表示Detect,指检测)、MTTA(A表示Acknowledge,指响应时间)、MTTI(I表示Identify,指识别和确认)、MTTK(K表示Know,指定位到根因)、MTTV(V表示Verify,指实施修复之后验证工作所需的时间),以及MDT(Mean Down Time)、MTRS(Mean Time to Restore Service,MTRS = total downtime / # of failures)、MTBSI(Mean Time Between Service Incidents,MTBSI = MTBF + MTRS)、等一批术语,原理大体相同。
- 优点:
- 倾向于描述系统整体可用性的宏观情况。
- 缺点:
- 与“系统故障率Incident-Ratio”指标一样,需要去定义故障,也仅适用于只有up/down二元状态的系统。
- 粒度粗。顾名思义,这批指标都是Mean/Average/平均值,可衡量宏观但不适用于描述某次具体故障。
2.4 错误预算Error-Budget
- 定义:
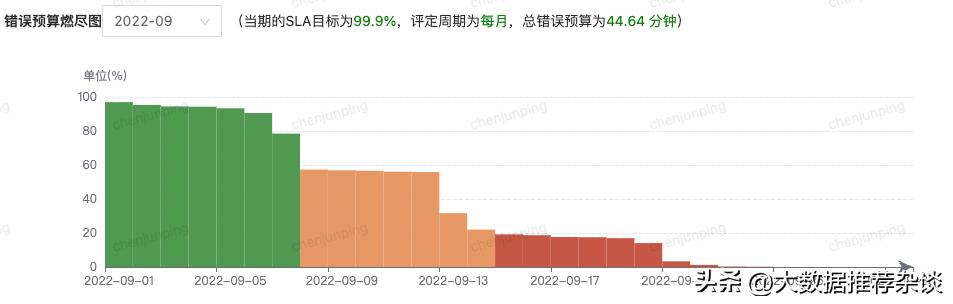
- 事先给产品设定可用率目标,如系统宕机时间一个月不得大于50分钟、用户下单每天失败次数不得大于1000次,这里的“50分钟”、“1000次”就是给团队的“预算”(最常用的量化维度是时间)。每次发生故障则相应扣除,通常用燃尽图展示,简称EB。
- 优点:
- 直观,易操作,多用作考察手段。
- 缺点:
- 粒度粗。无法描述每次具体故障及其影响。
2.5 服务水平目标SLA/SLO/SLI
- 定义:
- 第一步:为产品设定可用率目标(使用百分比),即Service Level Agreement(SLA),常见如一个月不低于99.99%(俗称“4个9”)表示一个月故障时长不得大于4.3分钟,这“4.3分钟”便视为给团队的“错误预算”(ErrorBudget,简称EB);
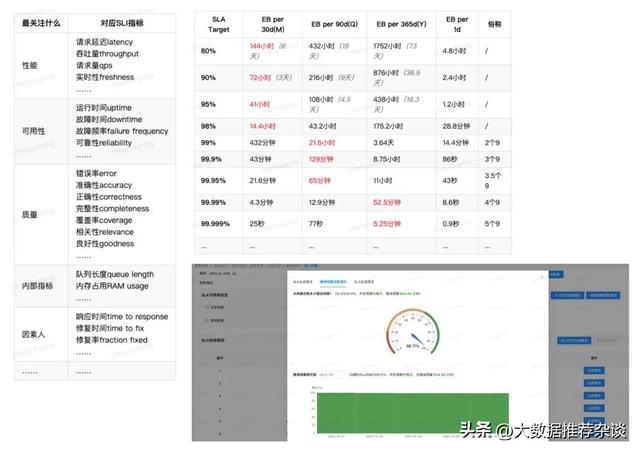
- 第二步:为产品选择最合适的几个黄金指标,即Service Level Indicator(SLI),最典型是Google SRE团队推荐的4大黄金指标,分别是Latency(请求延迟)、Traffic(流量)、Errors(请求错误率)、Saturation(资源利用率)。此外,还有很多指标,如Accuracy(数据准确性)、Coverage(覆盖率)、等等,详见下表。SLI并非选得越多越多,以网易严选为例,因为这是一个典型的在线电商产品,我们只挑选了最适合HTTP WEB类产品的两个指标Latency和Error去进行严选的SLA/SLO实践;
- 第三步:为每个黄金指标设置阈值,即Service Level Object(SLO),常见如下单请求Latency 99线不高于500毫秒(ResponseTime_99th≤500)、支付请求错误率不大于万分之一(5xx_Ratio<1?)。
- 第四步:持续监控这些目标是否真的达成,不能达成则自动扣除错误预算,直至耗光预算甚至跌至低于SLA承诺值,则将触发用户赔偿。因为SLA是一种有法律效应的商业承诺,一旦不能达成将按协议作相应赔偿,如提供消费抵价券、延长服务时长等,在各大云厂商官网都可以找到SLA承诺及赔偿方案,如亚马逊AWS SLA、阿里云ECS SLA、阿里云短信服务SLA、网易云信SLA等;
- 优点:
- 业界通行。尤其SLA,这是厂家和用户都认可的共同语言。
- 强烈的指导意义。SLA有绝对的考察意义,团队无法达成则将触发惩罚性措施(如对外用户赔偿、对内绩效扣分等),而EB燃尽速度也常用于控制新版本的发布变更频率、故障演练次数。
- 缺点:
- 不易操作。整套方法论不复杂,但是概念多,易踩的坑也多。挑选哪些sli,slo阈值设置多少,sla定什么周期几个9,都需评审,需联合多团队(负责人+研发+测试+运维±法务),并需要大量素材。
- 研发成本。与CMDB概念一样,业界没有绝对标准的落地方案,每家企业都有自己一套CMDB,实施SLA/SLO/SLI也都是“本土化”建设,研发成本有大有小,质量参差不齐。黑猫白猫能抓老鼠就行。
- 维护成本。不能一劳永逸,需定期展开复盘和评审,讨论SLI是否增补、SLO阈值是否修改、SLO是否需要增加规则去覆盖产品即将上线的新功能、SLA目标是否上调、以及上个月EB为什么消耗这么快等议题。
2.6 在离线状态Uptime/Downtime
- 定义:
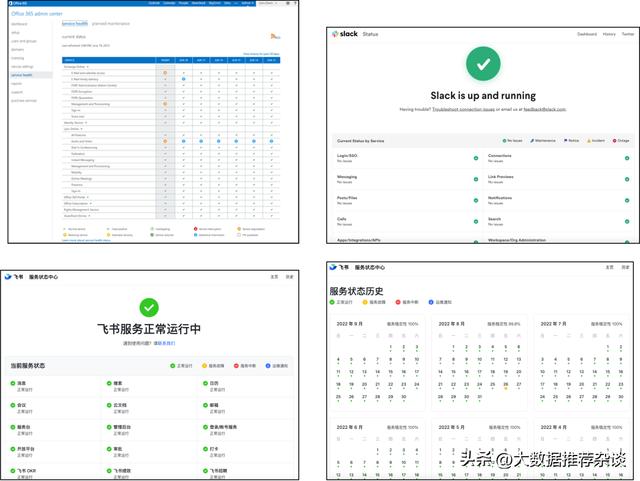
- 统计产品正常工作或者宕机的状态(Up/down),以及时间长度(Uptime/Downtime),并面向用户公开,通知渠道可以有多种,常见如邮件推送、RSS订阅、管理后台展示、官网展示等。
- 优点:
- 用户友好,直观。
- 缺点:
- 信息有限,量化不足。只知道一个产品挂了,不知道成功率是跌到99%还是80%,是全部接口都挂了还是只挂了写操作的接口而读操作接口正常。
2.7 归纳为两大类
可用性就是好服务在全部服务中的占比,高度抽象的公式如下:
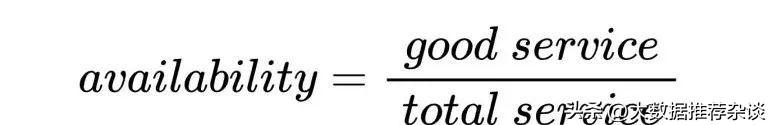
每一种量化指标都站在不同视角去定义和描述“好”good,归纳起来其实就是两大类:基于时间和基于数量。
2.7.1 基于时间time-based metrics
“故障恢复时间”、“在离线状态”、“服务水平目标”等指标都是基于时间维度,它们的计算公式可进一步具象为:
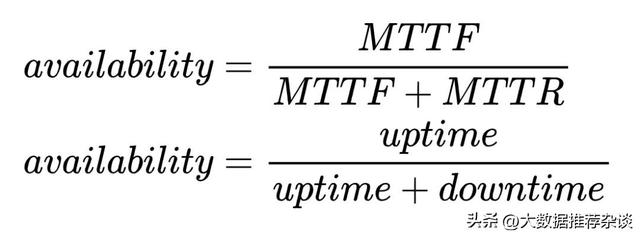
基于时间最大的问题在于:
- 无法反映故障的严重程度。同样是挂10分钟,这10分钟内系统功能是100%全挂还是只挂了10%;
- 无法反映用户的影响程度。同样是挂10分钟,夜间10分钟和白天高峰期的10分钟所造成的用户影响肯定不同;
- 指导性弱。仅凭“挂了10分钟”是看不出哪里挂了;
- 依赖人为判断。对于一个大型分布式系统而言,定义纯粹的二元状态up/down是困难的,毕竟通常只挂了某个产品功能(某个微服务)而不会全挂。只影响商品评论但不影响下单支付算不算故障?影响1000个用户才算故障还是只影响1个用户就算?只影响广东用户但不影响吉林用户算不算?上文提到的“下单请求Latency 99线不高于500毫秒(ResponseTime_99th≤500)”这条SLO规则的阈值为什么是500毫秒,而不是502毫秒?
2.7.2 基于数量count-based metrics
最典型的代表就是“请求成功率”,它的计算公式可具象为:

基于数量的指标不需要任何阈值,令他看起来浑然天成,统计起来也很方便,但它也有自己的问题:
- 数字对用户意义没那么大。一个产品的请求成功率为99%(感觉很高了),但这个产品在一天24小时里每一分钟都要挂一挂,一个运气很差的用户在0点到23点之间每个小时打开产品总会遇到一两次报错弹窗,对这个用户的体感来说,这个产品是挂了一整天。
- 数字会被高频用户意外放大。高频用户发出的请求数量可能是普通用户的1000倍,他们对分母和分子的贡献非常大,很容易淹没普通用户的贡献,汇总后的产品成功率有80%但可能高频用户全部100%成功了,而低频用户只有40%。
- 数字会受客户端行为影响而放大/缩小。两个极端场景,一个是用户看到页面报错弹窗后选择不断刷新页面或者点击按钮,这些重试行为会产生大量请求,而且全都是失败请求(此时系统还处于故障状态尚未得到修复),进而意外地拉低成功率。另一个极端是用户看到页面报错后干脆关闭离开,系统只剩下巡检系统每1分钟发来的一条探活请求,失败请求数量变少,进而意外拉高成功率。
3. 介绍一个新指标
察觉到现有指标存在不足之处,Google G Suite团队决定探索一套新指标。他们认为一个好指标必须满足3个条件,要能体现用户切身感受(meaningful)、数字与用户感受是成比例相关的(proportional)、具备故障源头指导意义(actionable),并且不需要人为设定阈值(否则太需要专家经验,容易过于武断,还需要长期跟踪和调优)。
3.1 用户可用时间user-uptime
3.1.1 定义
姑且先翻译为“用户可用时间”,计算公式如下:
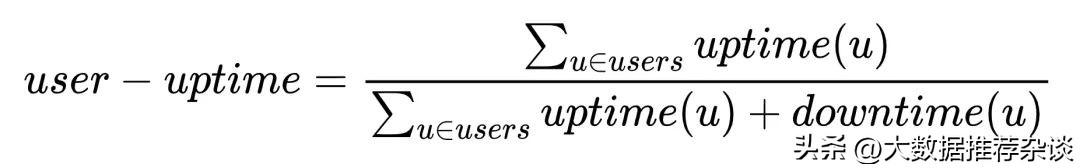
先计算出每个用户(per user)成功使用产品的时间,全部用户加起来求和,作为分子。再计算每个用户成功和失败的时间之和,全部用户加起来再求和,作为分母。二者相除的结果,就是user-uptime。
3.1.2 阐述
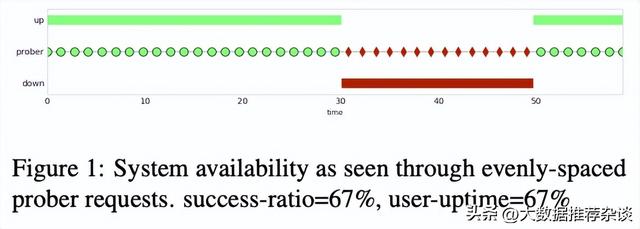
- 巡检系统,均匀地发送探针请求,每分钟1次。success-ratio=67%, user-uptime=67%,二者相同。
- 某个大活人user0,不均匀地随机发送请求,有疏有密。success-ratio=68%, user-uptime=65%,二者不同。
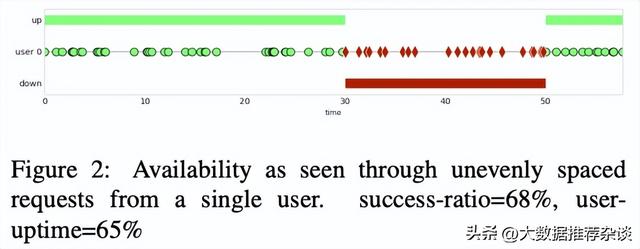
- 真实世界
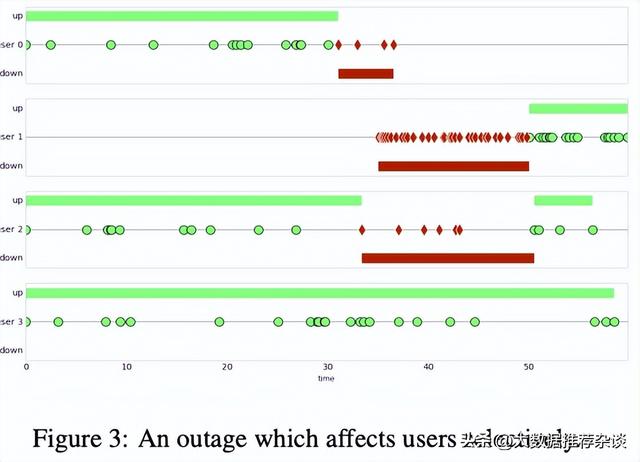
- 系统在第30分钟~50分钟之间发生了数据库故障,影响到商品查询服务和下单支付服务,但不影响小游戏、商品评论等其它功能。让我们看看同一个故障是如何对不同用户造成不同影响的:
- user0喜欢隔一会就刷新检查某款商品是否已补货,前面几次都顺利但突然报错,再重试3次还是失败,气跑了今天不再来了;
- user1今天首次打开网站就撞见这次故障,他一直报错并频繁刷新连续报错53次,皇天不负有心人第54次之后功能就正常了;
- user2与user0很像,本来开心地刷着商品列表但突然报错,重试5次后终于恢复正常,不再报错,还成功下单支付了;
- user3是个另类的用户,他打开网站不是来买东西而是玩一款内置小游戏,小游戏功能今天一切正常没有失败;
- 请问,user0/1/2/3四人的success-ratio是多少?user-uptime是多少?系统整体的呢?这四人谁的体感更差?
3.1.3 两个细节挑战
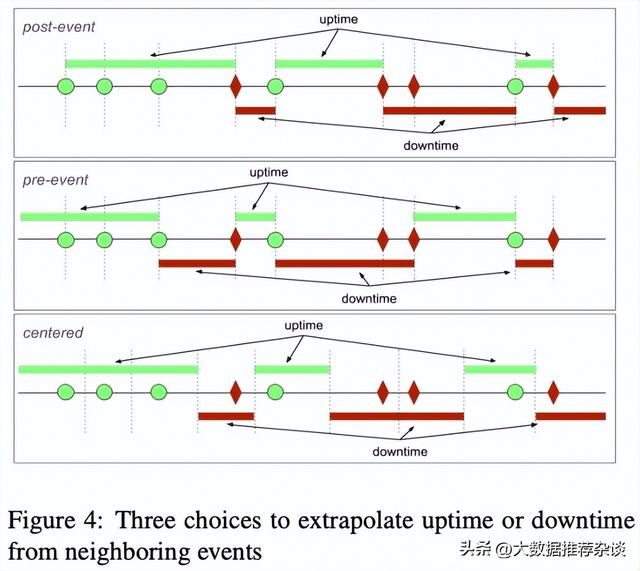
3.1.3.1 挑战1:判断持续时间
对同一个用户,最简单的情况就是两次相邻请求要么都成功要么都失败,这两次请求的间隔时间的长度就算为求和公式里的一个加数uptime(i)或者downtime(i)。但假如前一次成功后一次失败,或者前一次失败后一次成功,那这段时间算作uptime还是downtime呢?
无非三种选择:
- 在一次成功(或失败)的请求之后,我们就假定系统会一直保持正常(或故障),直到下一次请求来到并看到相反的结果。从一次成功请求到一次失败请求之间的时间长度视为uptime,一次失败请求到一次成功请求之间的时间长度视为downtime;
- 在一次成功(或失败)的请求之前,我们假定系统是一直保持成功(或故障),直到收到一次真实请求。一次成功请求之前的时间长度视为uptime,一次失败请求之前的时间长度视为downtime;
- 把两次结果相反的相邻请求(一次成功一次失败)之间的时间长度取中间值,一半视为uptime,另一半视为downtime;
这三种选择如下图所示,综合来看,我们选择第一种方案。
3.1.3.2 挑战2:活跃与不活跃阶段
如果一个用户很久不请求(离开电脑去吃饭了,关掉手机去睡觉了),隔了几小时或者几天才发来下一个请求,该用户的时间轴(提醒:在这套理论里,每个用户是有自己的时间轴的,用户之间的时间轴是独立不相干的)会出现一段很长很长的绿色(或红色)线段。
在这段期间系统对他来说是down还是up呢?或者问,这段时间要算为uptime还是downtime呢?似乎都不合适。谷歌团队引入了一个“cutoff时间”的新概念。如果一个用户两次请求相隔时间超过cutoff时间,这段时间忽略不用于计算uptime和downtime。一个系统可以选定自己的cutoff时长,谷歌团队选择的是用户在线交互平均时间间隔的99线(the 99th percentile of the interarrival time of user requests),对Gmail而言就是30分钟。
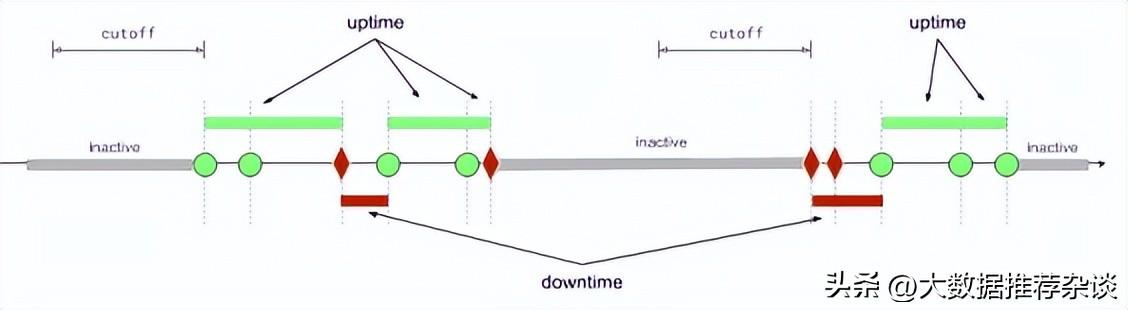
克服这两个挑战之后,我们就可以重新定义uptime、downtime及inactivetime:

我们可以说,这里的uptime是特指user-uptime,是站在用户侧看到的uptime,即对用户来说一款互联网产品对他而言,切切实实的正常工作时间。
3.1.4 实验例子
谷歌做了这么一个实验,模仿用户行为随机地向系统发起请求,并故意制造一场持续15分钟的故障(发生在30~45分钟期间),以下图为例,是其中2个用户(user0和user1)的请求分布情况,也是他们俩人使用产品的“亲身体验”。
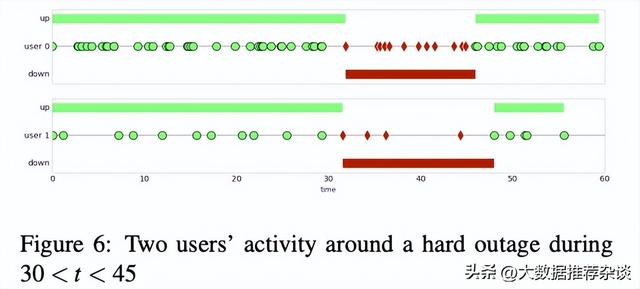
实验总时间是60分钟,系统故障时间是15分钟(即,系统正常时间是45分钟)。直观来说,这个系统的可用性的期望值应该在45÷60=75%左右。那么,实验结果是75%吗?
谷歌将这个实验重复做数千次,并统计出请求成功率(success-ratio)和用户可用时间(user-uptime)两个指标的可用性正态分布图。可以看出:
- 两个指标显示出Mean可用率分别是75.8%和74.2%,都在期望的75%左右,没有问题。
- 前者的Stdev标准差是0.078,后者只有0.049,右侧的柱状图分布更为“紧凑”。成功率会收到用户重试行为(故障期间重试必定失败)的影响而出现不少次实验的可用率下降在60%左右,导致左侧柱状图显得更“松散”,不能有效集中在0.75绿线旁边。
3.2 累积最小用户可用时间Windowed user-uptime&MCR
3.2.1 定义
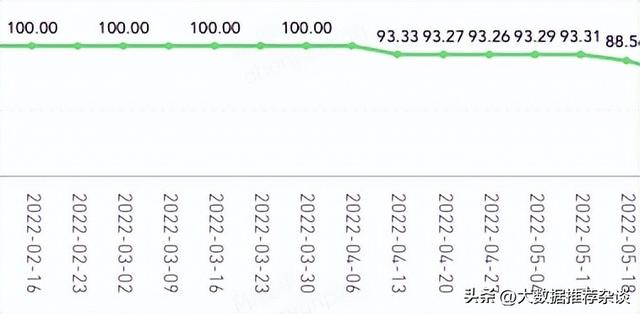
大多数互联网产品会计算一个特定周期的可用性,如每天、每周、每月、每季度。如下图,这是严选一个低优先级的内部服务的可用率周报表。这样的报表可以告诉我们可用性的抖动情况,但不能告诉某次事故的影响范围。
对稳定性管理员来说,他内心会希望拥有一张具备这样能力的新图表:呈现系统在过去1分钟的可用性最高是多少,同时呈现过去5分钟、10分钟、1小时、24小时、7天、90天的可用性最高达到多少?谷歌团队创新地引入了两个新概念:
- 新概念1:Windowed user-uptime。
暂且翻译为“窗口化用户可用时间”,缩写为WUU,先给产品选定几个时间长度作为“window窗口”(如1分钟/4分钟/15分钟/1小时/4小时/1天/1周/1月/1季度),将上一章节统计得到的“user-uptime”进一步量化,用窗口长度去平均切割过去一段时间(数日甚至数月)得到多个等长片段,计算每个片段里全体用户的user-uptime比率,得到多个比率(百分比)并从中找出最小值min,就是这个窗口粒度的Windowed user-uptime(WUU)。

- 新概念2:Minimal Cumulative Ratio(MCR)
暂且翻译为“累积最小用户可用时间”,缩写为MCR。将多个时间窗口按从小到大排列,将每个窗口找到的windowed user-uptime的点相连绘制呈线,这条曲线就是MCR曲线。
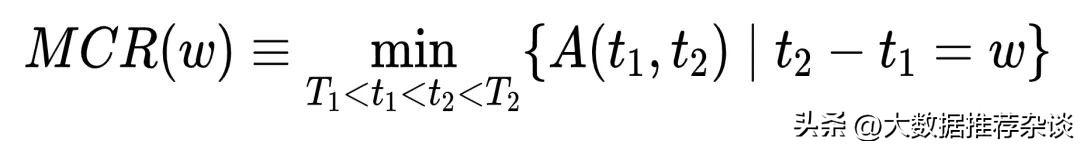
3.2.2 阐述
windowed user-uptime的思路是找到同一时间粒度上最差的那一次可用性,并绘制成MCR曲线。谷歌其实就是借鉴了编程语言Real-time Garbage Collector理论中的Minimum-Mutator-Utilization(MMU)思路,MCR和MMU在思路和计算上完全一样。
假如我们给自己的系统绘制MCR,为描述方便只选择过去3天的全部请求,选取的window窗口分别是1分钟、5分钟、15分钟、1小时、6小时和1天一共六个。那么,计算步骤如下:
- 第一步,计算“1分钟”窗口的WUU。首先,以“1分钟”为粒度去平均切割过去3天,一共得到24×60×3=4320个片段。接着,计算片段1(3天前00:00:00至00:01:00期间)的user-uptime比率,即00:00:00至00:01:00期间的uptime除以totaltime,假设结果是99.4%(这1分钟里系统发生了一次时间极短的小故障)。然后计算片段2(3天前00:01:00至00:02:00期间)的user-upitme比率,假设结果是100%(这1分钟里系统没发生任何问题,用户请求全部成功)。以此类推,计算出片段3、片段4、直至片段4320的结果。最后,从4320个结果(4320个百分比)中找出最小值,假设是92%(在2天前10:20:00至10:21:00期间系统发生了一次严重故障,影响了大量用户请求,导致这个窗口片段的user-uptime比率只剩下92%),这个92%便是“1分钟”窗口的WUU。
- 第二步,计算第二个窗口“5分钟”的WUU。过程相同,先以“5分钟”为粒度去平均切割过去3天,一共得到(24×60×3)÷5=864个片段。接着,计算出片段1(3天前00:00:00至00:05:00期间)的user-uptime比率,以及片段2、片段3、直至片段864的结果。最后,从864个结果中找出最小值,假设是94.3%,这个94.3%便是“5分钟”窗口的WUU。
- 第三步,以此类推去计算“15分钟”、“1小时”、“6小时”、“1天”这四个窗口的WUU,假设结果分别是96%、97.2%、99.2%和99.96%。
- 最后一步,绘制MCR曲线图。X轴为六个离散的时间窗口,Y轴为WUU。将6个WUU点(92%、94.3%、96%、97.2%、99.2%和99.96%)按顺序打上去并连成线。这条曲线即系统的MCR。
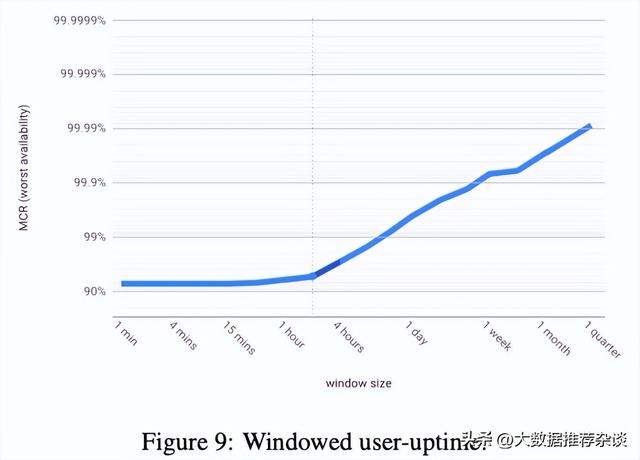
MCR概念比较新,未接触过这类最小值累积原理(类比GC MMU理论)的童鞋可能一下子不好理解,我们举一张MCR图来说下。从下图可以直观地看出3个信息点(常规的SLA可用率曲线图是无法直观呈现出这些信息的),这款产品:
- 整个季度的整体可用性达到99.991%(最右侧末段的点);
- 1分钟最差的可用性是92%(最左侧开端的点),没有比92%表现更差的分钟了;
- 拖垮系统可用性跌至92%的那次故障一共持续了约2个小时(曲线第一个拐点,它位于在1hour~4hours的中间位置),在半天以及更大时间尺度来看,系统可用性都维持在99%以上而不再出现大型故障(曲线在第一个拐点之后突然变陡,曲线斜率变大并迅猛地爬升);
既然系统稳定性管理员从上一张图已经得知系统发生过一次持续近2小时的故障,从MCR图表下钻到更细粒度的“每分钟可用性”详图便可以知道这次故障在某一天下午13:50开始发生功能异常(影响用户请求),在15:40开始逐步恢复,到16点附近系统可用性爬升回到99.9%理想水位,整个过程持续了约2个小时。
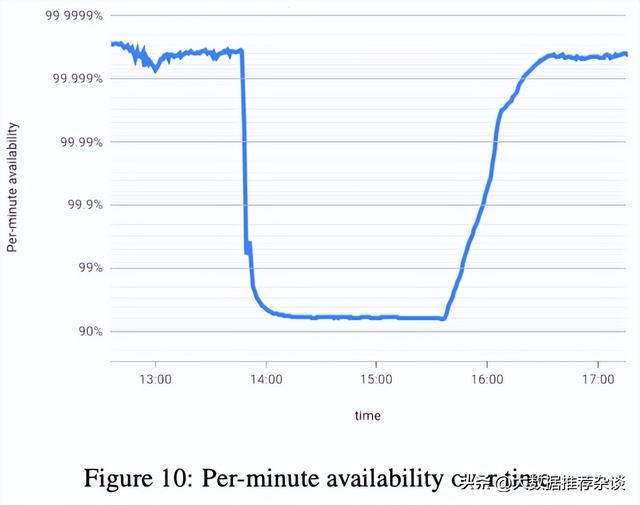
3.2.3 MCR单调递增
谷歌在数学上证明了MCR公式的单调性(monotonicity),篇幅太长这里不赘述,证明过程详见paper原文(5.2、5.3及尾部附录Appendix章节)。也就是说,只要窗口是越来越大,那么MCR曲线只会越走越高,斜率取决于系统真实可用性和故障程度。但MCR曲线是不会往下走的。
通俗地说,1hour的Worst Availability是不会比1分钟的更低。由于1分钟是包含在1小时之内的,如果1分钟的最差可用性为99%,那这1个小时也差不到哪去,肯定不会比99%更低,而只会比99%更高至少持平。
4. 指标的关系
4.1 分开来看
谷歌收集了全部Google G Suite产品(Calendar、Docs、Drive、Gmail、等)在2019年度的用户请求数据(已脱敏),并分别从用户可用时间(user-uptime)及请求成功率(success-ratio)两个角度去计算,向我们展示了这两项指标的作用,以及优劣势。
如开篇所言,Google G Suite团队原先就只有success-ratio图表但看着总觉得哪里不够用,指导性不够,才会去折腾琢磨user-uptime这个新指标。好消息是,试水结果很好,没有白折腾。
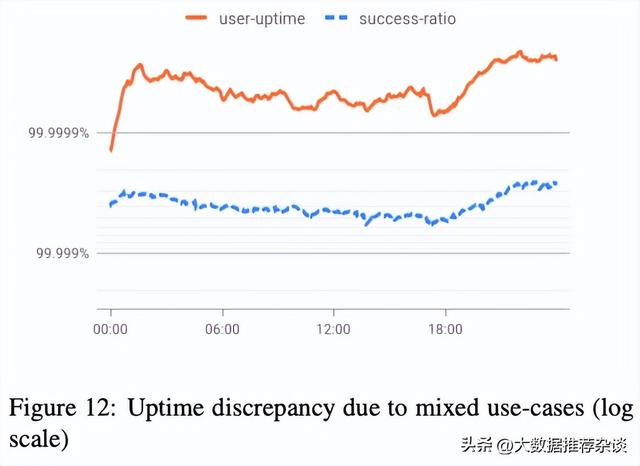
- 数据1:当描述系统整体可用性
可以看出,user-uptime橙线要比成功率的蓝线更高一些。这背后发生了什么?继续往下看。
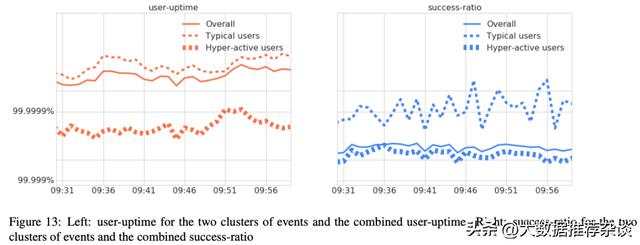
- 数据2:当描述超高频用户与常规用户
谷歌G Suite产品的用户构成是:
- 99%是常规用户,一段时间请求不多于100次。贡献了请求总量的38%。
- 1%是超高频用户,请求频率是普通用户的1000倍。贡献了请求总量的62%。
当发生系统故障(产品功能异常)时,这1%超高频用户会在短时间内刷出大量请求(失败请求),而当系统正常时,这1%超高频用户则会刷出大量成功请求。这些数量太大,在计算success-ratio成功率时极大稀释了另外那99%常规用户的表现。这样的稀释会误导系统的稳定性管理员,过高或过低地误判一次故障在用户的真实影响程度。
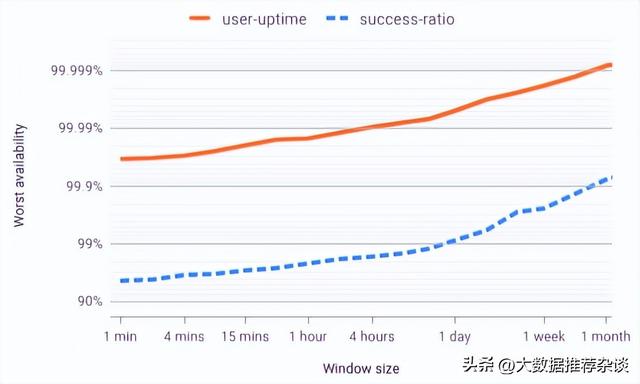
- 数据3:从MCR累积角度看
X轴是不同的窗口大小,可以看到橙线和蓝线形状和斜率相似,但橙线水位更高。
无论是数据1按时间分布,抑或数据3按窗口累计分布,可以看到user-uptime橙线都要比success-ratio蓝线更高一些。让我们下钻到每分钟的详图,在这个故障发生之前(下图最左侧)和故障恢复之后(下图最右侧),橙线蓝线基本吻合。但是,在故障持续期间两条线有明显偏差,为什么呢?进一步分析,发现是来自一批Google G Suite产品的滥用用户(abusive users),他们使用第三方邮箱产品并设置同步Gmail邮件,但这个第三方产品功能有bug,可以同步中低数量邮件的邮箱,但无法成功同步海量邮件的邮箱,同步过程会报错并立即重试(不断又循环失败下去),重试之前没有间隔一定的休眠时间。
这批滥用用户会拉低请求成功率(success-ratio)指标,并不断上下抖动,但由于请求失败的只是这一小戳用户,其余大量用户的请求全部都成功,用户可用时间(user-uptime)指标看上去就平稳。
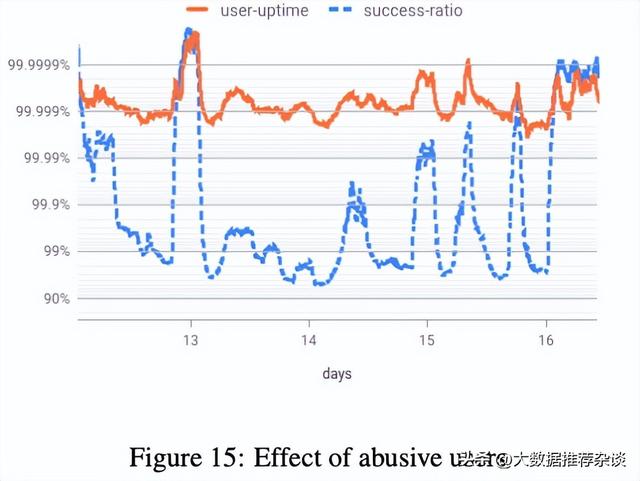
4.2 兼容并包,各取所长
从上文数据1、数据2和数据3的分析可以看出,请求成功率这个指标的最大问题在于容易受特殊用户(超高频用户、滥用用户、等)的行为干扰,而用户可用时间这个指标则更加稳健,不易受干扰。
借助上文这两项指标的数据对比,谷歌系统管理员便可以直观意识到有哪些极端用户和意外场景的存在,并进一步追查和优化,如联系第三方邮箱产品并沟通适配同步Gmail邮件的方式等。以前只有请求成功率这一张图,管理员是不易察觉到这样的深层次问题的存在的,可能会盯着蓝线单调地起起伏伏而熟视无睹,现在有了橙线的辅助,偏差一目了然。有偏差,就意味着哪里有问题。下面左图是把2个指标摆一起看,右图是把2个产品摆一起看,一对比,一些隐藏问题就可以跃然纸上。
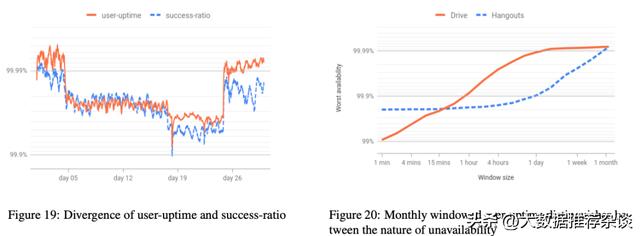
因此,这两个指标(其它指标亦然)之间不是非黑即白的矛盾关系,而都是系统管理员武器库中的成员,武器种类越多当然越好。而且,这些武器不是那种管理员手上拿着刀便举不了枪的互斥关系,而是手上拿着刀头上还戴多一副红外夜视眼镜的相辅相成关系,让黑夜里数据变得更直观,信息更透明。
4.3 已获得银弹和万能钥匙?
答案是否定的。尽管新指标有诸多优点,新指标与成功率等旧指标摆在一起呈现可以给管理员提供更多信息和线索,但不意味Success-Ratio、MTTF/MTTR、SLA/SLO等旧指标就一无是处,也不意味着User-Uptime新指标就无所不能。举个最常见的例子,某些故障令用户请求根本就达到不了系统(域名DNS失效、机房光纤挖断、等),这些也影响产品可用性和用户体验,但无论Success-Ratio还是User-Uptime都是“灯下黑,睁眼瞎”,需要其它手段。
5. 需求不断,创新不止
回顾Google G Suite团队整个指标创新的过程,我的感觉是这样的:
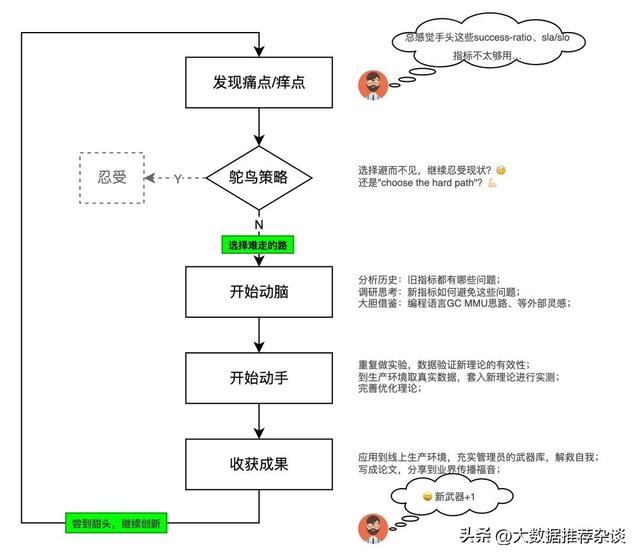
回到开篇管理员的那声嘀咕,假如你在工作中也浮现过这样的“别扭瞬间”,说明当前的工具或者方法还不够好,说明有创新空间在,说明自己和团队可以抓住这个宝贵的痛点痒点进一步深挖和创造。
可能今天介绍的User-Uptime新指标不一定适用于你的产品你的系统,但这个敢于创新的精神是普世的。再大的痛点也不慌,再小的痒点也不要错过,“从0到1是创新,从1到1.1也是”,与诸君共勉。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/23584.html
相关推荐
-
一机在手,考试无忧!衡阳率先实现人事考试移动端全流程服务
来源:【衡阳日报-掌上衡阳】 掌上衡阳9月20日讯(全媒体记者李建平 通讯员许晏) 一机在手,考试无忧。记者今日从市人社局获悉,前不久,试运行3个多月的“衡阳人事人才考试”微信和网…
-
阿里云个人邮箱登陆,阿里云个人邮箱登录网页版
走进学会,了解学会 市科协所属的学会、协会、研究会(以下简称“学会”),是由科技工作者自愿组成的社会团体,是科学共同体的重要组织形式。目前,市级学会已逾200家,在数量上为全国省级…
-
云主机销售系统(云主机销售系统_源码)
业务一线同学,经常说的一句话是“最难的不是搞定客户,而是内部沟通”,这几乎在任何厂商都是普遍现象。这一篇,就是要解这道题。 题图:《Wish You Were Here》, @Ka…
-
海外域名注册(海外域名注册公司)
想必人人都知道商标的重要性,早年那些知名大牌被抢注商标的事件也都略有耳闻。一旦商标被抢注就等同于为他人做了嫁衣,因此卖家们在塑造品牌的同时,也不能忘记首先要把商标给注册了。 今天就…
-
凡科网站登录入口(凡科互动登录)
对于一个企业来说,企业员工文化培训和学习是非常重要的。 通过学习企业文化知识,公司和员工不仅可以相互了解,还可以相互提高。 除了企业文化以外,企业的培训内容也是多种多样的,比如: …
-
路由器wan(路由器wan口和lan口的区别)
我和媳妇是双职工,媳妇工资略高于我。结婚后,我们按照家庭任务分工,各自工资各自拿,各司其职。媳妇每月工资负责家里开销,我负责房贷车贷!各自剩下的钱各自留着,照道理如此和谐相处本道相…
-
录像设备(同步录音录像设备)
提及便携式录像录音设备,相信很多人第一时间想到的就是智能穿戴摄像机。没错,今天速名网讲到的主要话题就是围绕智能穿戴便携式录像录音设备展开。不管是户外运动,还是平常的课堂,会议,培训…
-
宿迁服务器为什么怎么出名(为什么很多服务器在宿迁)_
? 9月8日上午,省公路事业发展中心组织召开宿迁市325省道大兴服务区及工区设计方案视频审查会议,与会领导、专家经认真审查、充分讨论后,认为方案内容齐全、总体可行,同意通过审查。 …
-
西子电梯服务器怎么试用系统(西子电梯服务器怎么试用系统启动)
泉城济南,泉甲天下 一座旧与新和谐交融的城市 它正洗去铅华 带着青色烟雨的独特韵味 注入与时俱进的新鲜血液 在这片热土上以自己的力量焕发青春 迈向更现代、更崭新的时代 近日,继三发…
-
盛夏科技在线布局工具下载(盛夏科技在线布局工具有哪些)
“暑假作业有不会做的记得给我发微信、打电话,下学期就五年级了,可以借教材来提前预习一下……”8月8日,酷暑难耐,高坪区斑竹中小学老师龙世强来到家住长乐镇白果桥村的学生丰彩琪家里进行…