
面试官提问
项目中存在哪些单点问题,怎么解决?
同城多机房、异地多活技术方案?
为什么需要单元化部署?解决了什么问题?
互联网应用从0-1发展到一定用户规模时,不可避免地面临各种单点瓶颈。“单点”问题在系统的不同发展阶段主要表现为以下形式:单体应用、单数据库、单机房和单地部署等,如图1-1所示:
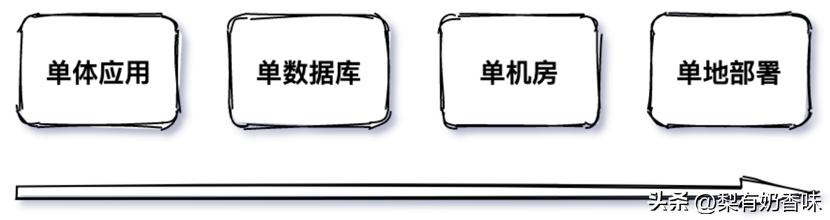

图1-1 系统发展过程遇到的单点问题
1. 单体应用
单体应用把系统中所有的功能、模块耦合在一个应用中,其存在问题是领域边界模糊,无法根据业务模块的需要进行伸缩。除此之外,还存在需求开发与上线发布冲突、整体打包编译费时等问题,不适用于大型复杂项目。
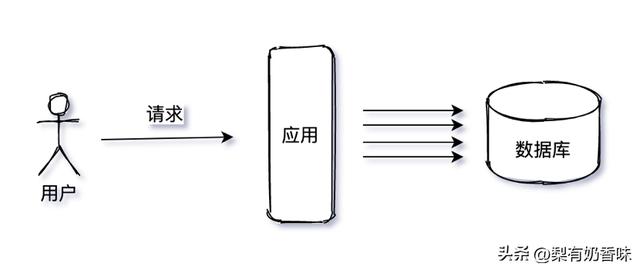
图1-2 单体应用
典型的系统架构如图1-2所示,用户请求从客户端发起至服务端,应用进程内部会产生多次业务逻辑运算,并且访问数据库。由于应用与数据库部署在同一个机房,系统内部处理耗时很小,请求链路上的耗时主要发生在用户到机房的物理距离上。
2. 单机房
服务化时代,巨大的单体应用被拆分为小型模块化的服务,如图1-3,每个服务都围绕特定的业务领域构建,服务之间通过远程过程调用(Remote Procedure Call,RPC)实现通信。尽管服务拆分使得原本进程内部的调用变成了网络调用,但是应用都部署在同一个机房,可以忽略RPC网络开销。
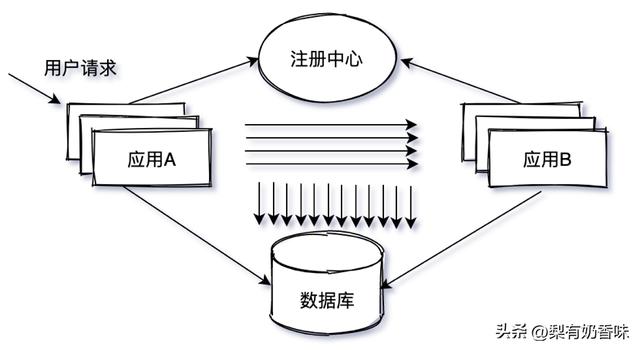
图1-3 单机房服务化
服务化解决了应用层的瓶颈,紧接着数据库就成为制约系统扩展的瓶颈。
3. 单数据库
随着业务的发展数据会不断增多,由于单机物理服务器的资源,如CPU、磁盘、内存、IO 等有限,会造成磁盘读取和网络IO 出现瓶颈,而单表的数据量太大,查询时扫描的数据就会很多,导致非索引字段查询、join、group by、order by等 SQL执行效率低下,出现CPU瓶颈。
通过引入数据库中间件,实现对上层业务透明的分库分表可以解决上述问题。数据的分片(Sharding)常以用户ID 哈希取模确定数据所在物理节点,若前缀或者后缀具有良好的离散性,也可以去前后缀来切分数据。如图1-4所示,假设以末两位作为分片维度,可以在逻辑上将数据提前一次性拆到100个分表中,这100个分表可以先位于同一个物理库中,随着系统的发展,逐步拆成2个、5个、10个,乃至100个物理库。而数据访问中间件会屏蔽表与库的映射关系,应用层不必感知。
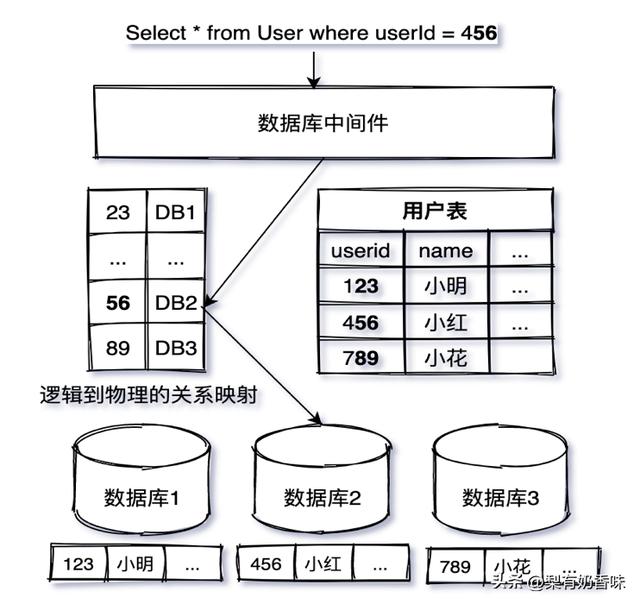
图1-4 分库分表解决数据库单点瓶颈
以上解决了应用层和数据库层单点,但物理机房又成为制约系统伸缩和高可用能力的最大单点。
4. 同城多机房
要突破单机房的容量限制,在同城新建多个机房,机房之间通过专线连成同一个内部网络,如图1-5所示,将应用部署在多个机房内,数据库主备交叉部署到不同的机房,依靠不同的服务注册中心,将应用层逻辑隔离。这样只要请求进入一个机房,应用层就一定会在同一个机房内处理完。我们只要在入口处调节进入两个机房的请求比例,就可以精确地控制两个机房的负载。
由于数据库主库只在其中一个机房内,数据写入时只写主库,主备数据同步,异地机房备库可提供读服务。该方案存在的缺点是访问数据库存在跨机房调用、主备数据同步延迟。由于多机房部署,数据层与应用层均可自由扩容。(后文会分析,扩容其实会存在限制)。
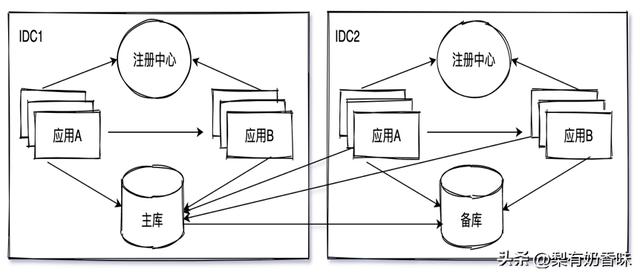
图1-5 同城多机房应用架构
多机房优点总结:
a、避免机房掉电、网线挖断等单机房故障导致全域产品线不可用
b、容量:单机房受机架限制无法持续扩展机器扩容
c、就近接入:用户访问离自己较近的机房减少网络耗时,保障用户体验
5. 单元化
如图1-6所示,应用层每增加一台机器就要与一定数量的数据库建立连接, 数据库连接数瓶颈又限制了系统的水平扩展能力。
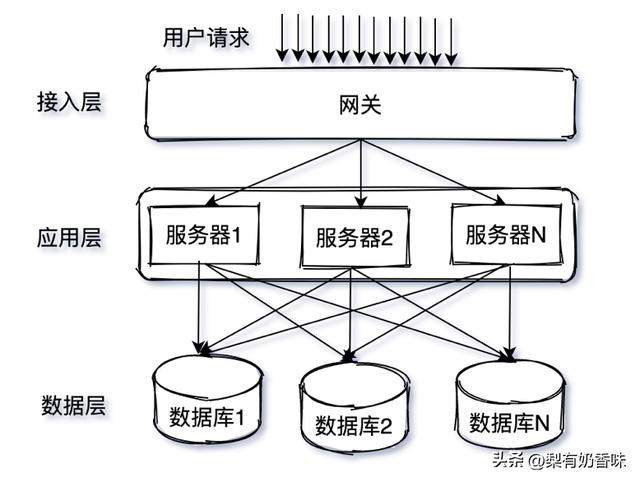
图1-6 每台服务器都需要和数据库建立连接
尽管数据库可以水平拆分,但应用层流量是完全随机的。任意一个应用节点可能访问任意一个数据库节点,这就意味着每扩容一台机器就需要占用一定数量的数据库连接,而数据库连接数是有上限的,这样导致的新问题是不能再对应用集群扩容。因此同城多机房部署无法彻底解决扩容问题。如图1-7所示,单元化架构设想应用层也能像数据层那样分片,把整个请求链路收敛在一组服务器中,从应用层到数据层就可以组成一个封闭的单元。数据库只需要承载本单元的应用节点的请求,从而大大节省了连接数。“单元”可以作为一个相对独立整体来挪动,还可以把部分单元部署到异地来实现异地容灾。
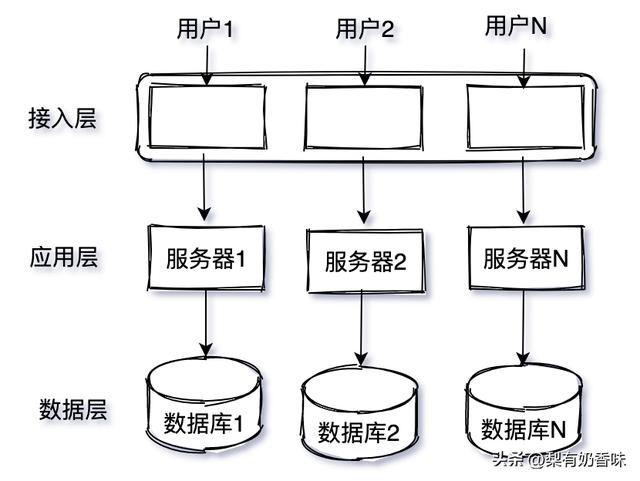
图1-7 服务单元化
单元化有几个重要的设计原则
1. 业务必须是可分片的,并且分片均衡,常以用户ID或者地区作为分片维度
2. 整个系统都要面向逻辑分区设计,方便单元挪动。
3. 理想状态单元内部是自封闭的,单元内可以完成业务的所有操作。但有时跨单元调用无法避免,如图1-8,用户转账。
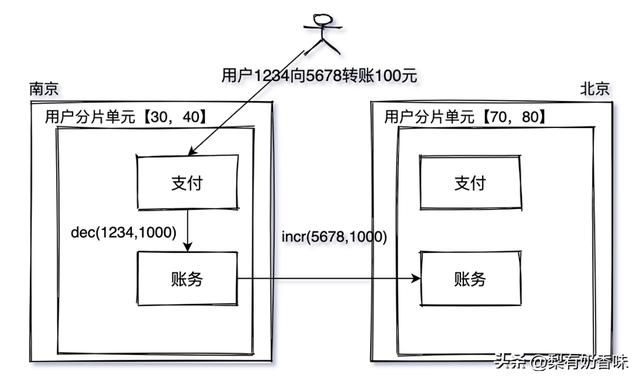
图1-8 跨单元服务调用示意图
假设使用用户ID对业务分片,拆分单元,应用层根据userId将请求路由到承接流量的单元,转账场景中用户ID 为1234的用户转账给用户5678, 这对用户数据极有可能不在同一个单元内,跨单元调用无法避免。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/21789.html
相关推荐
-
数据工厂包括什么(数据工厂包括低能耗数据中心)
基于对运营推广系统的业务逻辑设计、角色职能和功能权限的了解后,本文从四个角度重点解析数据工厂系统,带你设计实现这套数据工厂系统呢,希望对你有所帮助。 上文我们已经讲了运营推广系统的…
-
万德数据库多少钱一年(万德数据库多少钱一年_个人)
所谓 “搜商(SQ)”就是搜索智力,指的是通过某种手段获取有用信息的能力 。 我们处在一个信息爆炸的时代,寻找信息是互联网时代的必备技能。 你可能会说这有什么,不就是google、…
-
tokyo是什么国家(tokyo是什么国家怎么读)_
平时喜欢刷TikTok的朋友们,一定见过下面这个小孩子。 他虽然只有7岁,却是近期最火的顶流。包括小in在内的无数网友,心都被他拿捏得死死的! 其实他并不是童星,更不是哪家的星二代…
-
丽萨扮演者是(丽萨扮演者是哪国人)
原来,我们这和全国很多地方一样,今天是小学秋季第一天上课。我们这里虽然也有几所初中,但是开学的时间不一样,有些也是今天开学。不过和很多地方不一样的是,我们这里的初中今年第一次按地段…
-
石家庄服务器托管收费(石家庄服务器托管公司)
上海的医疗资源在全国首屈一指,应对疫情已经力不从心了,真要放开,全国会是什么样的情景,大量的农村,县域会是什么样的情景,自行脑补。为什么会一次次大范围扩散,从自己经历的一些事,来聊…
-
任务计划程序找不到远程计算机(电脑任务计划程序找不到远程计算机)_
泽众ALM如何进行项目进度、计划和报工的管理? 泽众ALM 说起项目管理,计划、进度和报工就是abc,很基础的东西了。但是越是基础的东西,越不容易做好,因为细节太多了。 先说计划。…
-
三年又三天安与骑兵(安与骑兵星光大道)_
凌晨四点半 你从梦中惊醒 梦里梦到的人 是醒来不能说话的人 同在一座城市无法相见的人 写了又删的信息 是说不出口的心里话 爱而不得相思无果的傻话 天色渐渐泛白 你缓缓推窗 有风微凉…
-
服务器端测试用例设计(服务器端测试用例设计方案)
对Web应用程序运行自动化的端到端测试时,最常见的问题之一是如何处理测试数据。 端到端测试通常会在通过应用程序中的测试用例时创建,更新和删除各种信息。 不可避免地,您会遇到问题,因…
-
创业网站源码(加盟网站源码)
本人设计10年以上经验,主要从事平面广告+3D舞美设计+网站UI和程序方面的设计。 接私单大致分为: 线上接单是这些: 1,设计大赛 这种高大上的比赛,在站酷或其他大型设计网站会有…
-
亚马逊免费服务器试用方法视频(亚马逊免费服务器试用方法视频教程)
“ 我不会英语可以做亚马逊吗?” “ Listing 看不懂,不知道怎么优化?” “ 不知道怎么去形容这个产品的卖点?” 还在被这些问题困扰的亚马逊卖家们注意啦! 今天给大家介绍的…