
电子发烧友网报道(文/李弯弯)AI、5G等新兴产业的蓬勃发展催生了海量数据计算需求,同时AI算法模型持续迭代,复杂化日益凸显,数字经济时代下市场需要强大、普惠的算力引擎。而从供给端来看,先进制程的迭代周期变长,使得芯片能效比的提升并不显著。
针对AI应用特点实现硬件架构创新是必然趋势,墨芯人工智能CEO王维在某论坛上谈到,依托对AI的理解用软硬一体解决算力瓶颈问题是行业公认的发展方向。他认为,稀疏化能够有效应对算力瓶颈,实现原理是,不存储和不处理零值,从而得到更小且更快的模型。
软硬一体化稀疏路径符合AI计算核心诉求
软硬一体化稀疏路径符合AI计算高吞吐、低功耗、低延时的核心需求。AI稀疏产业化的成功要素包括:1、跨算法、软件、硬件领域的协同开发;2、拥有持续多层次优化稀疏运算的底层算法能力;3、架构需保证可编程性、高度可拓展属性及快速迭代能力。
稀疏化路径已具备批量化工程应用能力。英伟达在2020年推出的A100产品中,就率先引入稀疏Tensor Core实现4:2结构化稀疏,稀疏是神经网络轻量化的重要手段,英伟达稀疏化产品有效引领市场应用趋势。稀疏化架构可与现有AI软件生态深度适配,例如英伟达直接使用Tensor Core进行稀疏矩阵乘累加操作,无需进行底层编程。

基于双稀疏特点,自研核心AI架构
墨芯是全球最早研发稀疏化算法及架构的企业,并在2018年开始稀疏化的全球专利布局,该公司也是最早商用稀疏化产品实现销售的,第一款FPGA产品在2019年Q4开始产生销售。
王维表示,现有芯片架构设计在稀疏化支持中面临较大局限,比如CPU架构,可支持跳点运算,但因其算力限制,仅能够支持边缘端应用,无法支持更大的模型,再比如GPU架构,只能进行并行计算,所有元素(包括0元素)均参与运算,无法实现高倍数加速。
基于双稀疏特点,墨芯自研核心AI架构。其双稀疏架构设计理念:平衡的权重和激活张量剪枝技术,可将精度损失降至最低的前提下保持对硬件的友好度;墨芯独有的剪枝和压缩技术可以再许多网络和应用中实现最多高到32倍的稀疏。
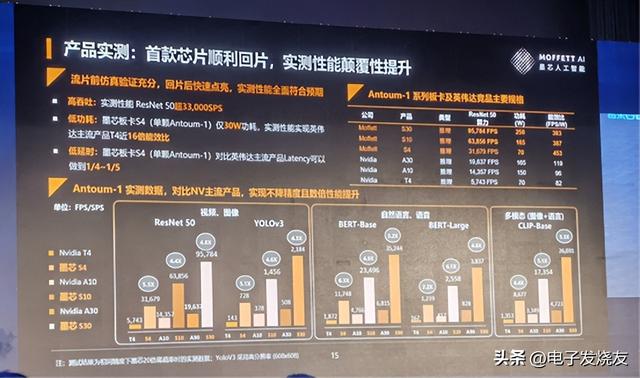
墨芯首款稀疏化云端AI芯片Antoum-1已经回片,实测性能ResNet 50超33000SPS;墨芯板卡S4(单颗Antoum-1)仅30W功耗,实测性能实现英伟达主流产品T4近16倍能效比;墨芯板卡S4对比英伟达主流产品Latency可以做到1/4-1/5。

墨芯人工智能CEO王维演讲(电子发烧友拍摄)
稀疏化计算产品商业落地,将赋能AI产业变革。一、助力云服务商降低单位算力拥有成本,2021年,Nvidia在中国营收超过38亿美金,其中阿里,腾讯等头部互联网公司采购金额基本超过1亿美金。随着AI持续发展,数据量的指数上升导致AI芯片的需求会持续上升,云服务商采购额将逐年增加,因此他们对降低成本的诉求非常强劲,基于Antoum-1的推理卡S4相较于英伟达对标推理卡T4,ResNest50及BERT每FPS/SPS成本降低约85%。
二、助力云服务商缩减能耗成本,电费支出是数据中心最大的营业成本,平均数据中心近60%的营业成本是电力成本,降低能耗是数据中心和云服务商的最大痛点,2021年全国数据中心的耗电量占社会总用电的近3%,且增长率已连续8年超过12%,基于Antoum-1的推理卡S4相较于Nvidia主力推理卡T4,ResNest50及BERT每FPS/SPS能耗成本降低约90%。
小结
目前基于稀疏化的AI架构主要面向云端训练场景,不过理论上来说,稀疏化训练由于能大幅降低对内存、带宽与计算的需求,十分适合训练,未来墨芯在满足推理市场的需求后,将切入训练市场,建立稀疏训练生态,产品在软件层面对训练做更多的开发,支持训练专用的算子,同时硬件上也会为训练定义架构。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/20664.html
相关推荐
-
阿里云矢量图标库(阿里云矢量图标库用法)
稳定性、性能、包大小,在移动端基础用户体验领域“三分天下”,是app承载业务获得稳定、高效、低成本、快速增长的重要基石。其中,包大小对下载转化率、拉新拉活成本等方面的影响至关重要,…
-
qq云存储登陆(qq云存储怎么用)
不得不说,现在的个人数据实在是太占存储空间了。笔者还记得自己2013年购买智能机的时候,市场普遍都是32GB或者64GB的标配,如果没有太多存储需求,甚至16GB也能用。然而,随着…
-
阿里论坛社区(阿里_论坛)
2022年Q3财报发布后(2023财年Q2),舆论场中对阿里阿里评判越发分裂: 乐观,经营利润率转好,在减负增效中既然“增效”不易,先抓住“减负”也未尝不可,该季度阿里以“稳”为主…
-
ip站长查询工具(站长工具ip地址查询)_
医院类型的网站,专业性质很强,能获得的精准ip也是比较少的。小站长和大家一起来聊聊医院网站怎么运营比较好。 1:网站的关键词定位:这也是最重要的开始,我们做一个网站总会有一个目标,…
-
局域网查看器(qq密码局域网查看器)
在使用电脑的过程中,我们经常会遇到各种各样类型的文件,比如常见的JPG图片格式、mp3音频格式、mp4视频格式、word、、Excel、PSD等,这些文件都需要专门的应用软件来打开…
-
中文域名转码(中文域名转码器)
我以discuz后台提供的数据库导出方法为例先分享一下我转码的过程,后面也会讲另外几种数据库导入导出的方法。首先关闭站点 站长,数据库,备份,强制UTF8 备份完成的数据库文件在根…
-
鳄鱼主机php扩展(鳄鱼主机提现审核需要多久)
作 者 林雪萍:北京联讯动力咨询有限公司总经理,天津大学精仪学院兼职教授 看不见的产业和沸腾的湖下熔岩 连接器无处不在,是电子电气世界的神经网络。无论是手机,还是汽车,都隐藏着无数…
-
管家婆辉煌版官网(管家婆辉煌网络版安装)
一个老客户qq找我说修复管家婆升级出错多少钱。出错如下图。我报价200。然后老客户就发账套过来我看下。 然后我开始紧张的修复工作.。然后修复好后,发截图给他确认。 确认好数据后,这…
-
申请个人网页三D胆,申请个人网页孙婷婕
相信亚马逊卖家对A+页面都不陌生,A+页面是一种图文并茂的产品描述页面,可以展示给买家更直观的产品,也更利于提升产品的转化率。 但一些新卖家对A+页面并不是很了解,下面花几分钟跟大…
-
前端脚手架有哪些(前端脚手架有哪些种类)
自主搭建5个精品脚手架,玩转前端提效 下栽地止:https://www.666xit.com/3796/ 覆盖前端研发全流程环节,可通用、可复用当下的前端开发,离不开脚手架。初级前…