
前言
很多开发人员都知道索引对于数据库的查询性能至关重要,一个好的索引能使数据库的性能提升成千上万倍。但给数据库加索引是一项相对专业的工作,需要对数据库的运行原理有一定了解。同时,加了索引有没有性能提升、性能提升了多少,这些都是加索引前就想知道的。这项繁杂的工作有没有更好的方案呢?有!就是今天重磅推出的索引推荐。
索引推荐这项技术概括起来就是通过分析SQL,枚举可能的索引组合,并通过优化器What-If的能力,选出其中收益最高的索引组合推荐给用户。索引推荐可以极大降低用户的使用门槛,增加数据库智能化能力。RDS PostgreSQL在新版本中已经自带索引推荐功能,可以通过访问PostgreSQL数据库亦或通过RDS控制台使用索引推荐功能。
技术原理
1、索引推荐流程
1、分析 Indexable Column,分析出SQL中哪些列可以利用索引,例如:
- Where条件中的 =, >, <, between, in等列
- Order By的排序列
- Group By的聚合列
- MIN,MAX函数列
- Join的Condition列
2、构建 Candidate Index
- 从IndexableColumn中构建出所有可能的Candidate Index
- Candidate Index分为单列索引和联合索引,单列索引包括所有Indexable Column,联合索引以一定规则组合Indexable Column
3、优化器What-If选择最优
2、优化器What-if能力
G查询优化是基于代价的,分为启动代价,运行代价,总代价,计算方式为{CPU cost + IO cost}。
- 启动代价:读取到第一条元组前花费的代价,比如索引扫描节点的启动代价就是读取目标表的索引页,获取到第一个元组的代价。
- 运行代价:获取全部元组的代价。
- 总代价:二者之和。
索引的代价计算是由固定公式得来,只要构造索引时补充公式需要的变量,就可以利用到优化器的What-If能力。
方案实现
1、总体流程
1、采用通用的索引推荐流程,注册planner_hook,遍历查询树,构造索引项,依赖优化器的What-If能力得到结果。
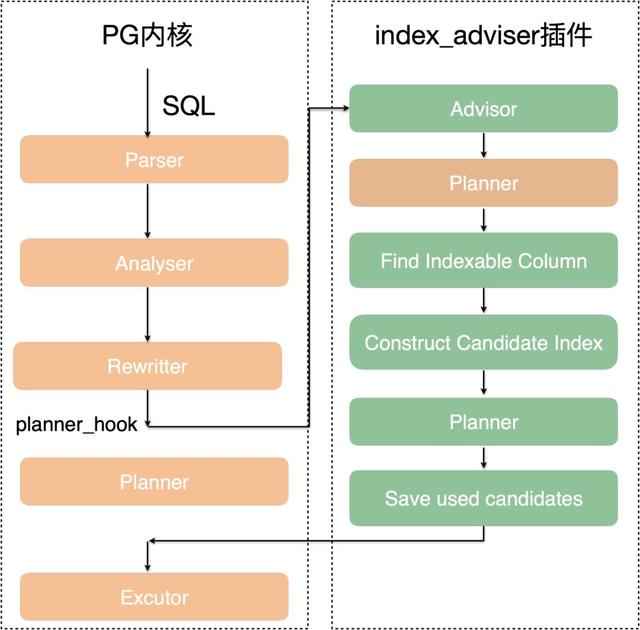

2、智能化索引推荐
采用通用的索引推荐流程,注册planner_hook,遍历查询树,构造索引项,依赖优化器的What-If能力得到结果。

2、详细设计
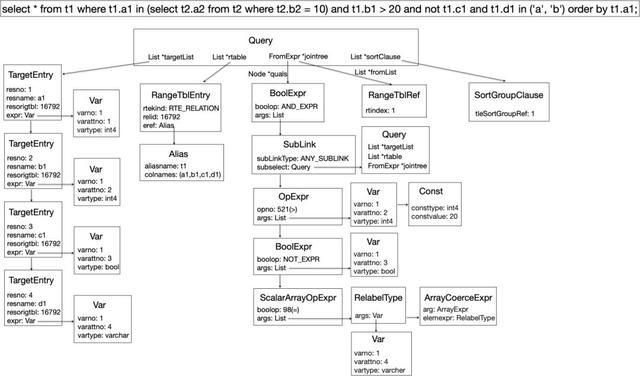
从查询树到candidate index
针对一条SQL,我们利用内核构造的查询树,精确找到哪些列可以成为索引,制造出索引候选项,交由优化器选择。
最佳实践
1、从RDS控制台进行可视化操作
进入RDS实例详情页面 -> 自治服务 -> 慢SQL ,可以在此处获得相关操作指引。

2、实操步骤
1、创建表
CREATE TABLE t( a INT, b INT );
INSERT INTO t SELECT s, 99999 - s FROM generate_series(0,99999) AS s;
ANALYZE t;
所生成的表包含以下各行:
a | b
-------+-------
0 | 99999
1 | 99998
2 | 99997
3 | 99996
.
.
.
99997 | 2
99998 | 1
99999 | 02、查询单条SQL建议说明
如果希望索引推荐分析查询并提出索引编制建议但不实际执行查询,将EXPLAIN关键字作为SQL语句的前缀,示例如下:
postgres=# EXPLAIN SELECT * FROM t WHERE a < 10000;
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1693.00 rows=9983 width=8)
Filter: (a < 10000)
Result (cost=0.00..0.00 rows=0 width=0)
One-Time Filter: '** plan (using Index Adviser) **'::text
-> Index Scan using "<1>t_a_idx" on t (cost=0.42..256.52 rows=9983 width=8)
Index Cond: (a < 10000)
(6 rows)postgres=# EXPLAIN SELECT * FROM t WHERE a = 100;
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1693.00 rows=1 width=8)
Filter: (a = 100)
Result (cost=0.00..0.00 rows=0 width=0)
One-Time Filter: '** plan (using Index Adviser) **'::text
-> Index Scan using "<1>t_a_idx" on t (cost=0.42..2.64 rows=1 width=8)
Index Cond: (a = 100)
(6 rows)postgres=# EXPLAIN SELECT * FROM t WHERE b = 10000;
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1693.00 rows=1 width=8)
Filter: (b = 10000)
Result (cost=0.00..0.00 rows=0 width=0)
One-Time Filter: '** plan (using Index Adviser) **'::text
-> Index Scan using "<1>t_b_idx" on t (cost=0.42..2.64 rows=1 width=8)
Index Cond: (b = 10000)
(6 rows)可通过psql命令行查询index_advisory表内存储的索引编制建议,示例如下:
postgres=# SELECT * FROM index_advisory;
reloid | relname | attrs | benefit | original_cost | new_cost | index_size | backend_pid | timestamp
--------+---------+-------+---------+---------------+----------+------------+-------------+----------------------------------
16438 | t | {1} | 1337.43 | 1693 | 355.575 | 2624 | 79370 | 18-JUN-21 08:55:51.492388 +00:00
16438 | t | {1} | 1684.56 | 1693 | 8.435 | 2624 | 79370 | 18-JUN-21 08:59:00.319336 +00:00
16438 | t | {2} | 1684.56 | 1693 | 8.435 | 2624 | 79370 | 18-JUN-21 08:59:07.814453 +00:00
(3 rows)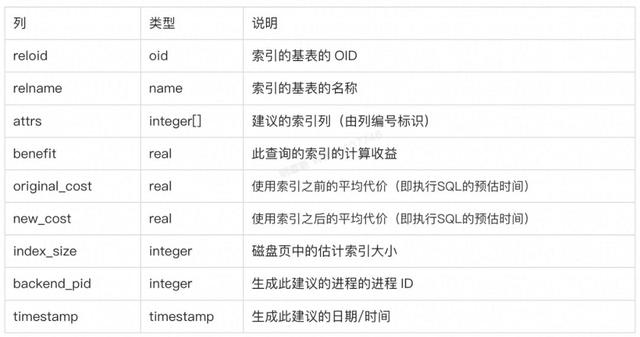
如果语句不带EXPLAIN关键字前缀,索引推荐将在语句执行期间分析语句并记录建议。
3、查询WorkLoad级别建议
通过show_index_advisory()函数获取单个会话的WorkLoad建议,此函数用于获取单个会话的索引推荐(由后端进程ID标识),可通过指定会话的进程ID来调用该函数:
SELECT show_index_advisory( pid );其中,pid 是当前会话的进程 ID。如果不知道当前会话的进程 ID,则传递值 NULL 也将为当前会话返回结果集。
postgres=# SELECT show_index_advisory(null);
show_index_advisory
----------------------------------------------------------------------------------------------------------------------------------------------------
create index idx_t_a on public.t(a);/* size: 2624 KB, benefit: 3021.99, gain: 1.15167301457103, original_cost: 1693, new_cost: 182.005006313324 */
create index idx_t_b on public.t(b);/* size: 2624 KB, benefit: 1684.56, gain: 0.641983590474943, original_cost: 1693, new_cost: 8.4350004196167 */
(2 rows)说明 结果集中每行的表示意义如下:
- 创建索引推荐建议的索引所需的SQL语句。
- 索引页的估计大小。
- 使用索引的总收益(benefit)。
- 使用索引的增益(gain=benefit/size)。
- 使用索引之前的平均代价(即执行SQL的预估时间)。
- 使用索引之后的平均代价(即执行SQL的预估时间)。
通过select_index_advisory视图获取所有会话的WorkLoad建议,此视图包含计算的指标和CREATE INDEX语句,展示当前位于index_advisory表中所有会话的索引编制建议。表t中列a和列b的索引编制建议显示如下:
postgres=# SELECT * FROM select_index_advisory;
backend_pid | show_index_advisory
-------------+----------------------------------------------------------------------------------------------------------------------------------------------------
79370 | create index idx_t_a on public.t(a);/* size: 2624 KB, benefit: 3021.99, gain: 1.15167301457103, original_cost: 1693, new_cost: 182.005006313324 */
79370 | create index idx_t_b on public.t(b);/* size: 2624 KB, benefit: 1684.56, gain: 0.641983590474943, original_cost: 1693, new_cost: 8.4350004196167 */
(2 rows)在每个会话中,从同一建议的索引中受益的所有查询的结果将被组合起来,以便按每个建议的索引生成一组指标,此指标反映在名为benefit和gain的字段中,字段公式如下所示:
size = MAX(index size of all queries)
benefit = SUM(benefit of each query)
gain = SUM(benefit of each query) / MAX(index size of all queries)说明 如果单条SQL建议同时创建多个索引,则index_advisory表中记录的new_cost为创建了多个索引之后的代价,而非创建某一个索引之后的代价。
当对给定会话期间得到的不同建议索引的相对优势进行比较时,gain指标十分有用。gain值越大,从索引中得到的成本效益就越高,这可以抵消索引可能消耗的磁盘空间。
未来展望
阿里云RDS PostgreSQL的索引推荐功能未来还会朝着以下几个方面进行扩展:
- 支持GIN、GIST、BRIN索引的推荐。BRIN索引为block索引,对于无法评估数据分布的场景无法推荐;GIST是数据聚集后的结果,也需要对数据分布有所了解;
- WorkLoad级别的推荐可以更加细化,当前是以benefit做聚合和排序,得出索引推荐,后续可以更加精细化。
作者信息
赵锐,花名:惜元,专注于RDS PostgreSQL内核研发,热爱和分享PostgreSQL数据库相关技术。欢迎有志之士加入RDS产品部!联系邮箱:vogts.wangt@alibaba-inc.com


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/17880.html
相关推荐
-
服务器调试用什么调试软件(服务器调试用什么调试软件好)
gRPC 接口调试 grpc 作为一个老程序员,最近公司技术架构用到了gPRC,但国内很少有支持这个的工具,大部分都只是支持http。由于我同时也是Apipost骨灰级用户,于是就…
-
阿里云浏览器(阿里云浏览器手机版)
曾经是中国市值一哥的阿里,股价持续下滑,现在已跌到不及高峰期市值的四分之一。因此网络上有不少人唱衰阿里,觉得阿里下行趋势已无法逆转,前景暗淡。至于阿里公司为什么会衰落如此,其中的原…
-
cps平台有哪些(cps平台是什么意思)
cps是通过实际的销售量进行收费的,需要精确的流量进行数据统计转换,小说cps主要是先对接好小说平台,然后吸引用户通过我们搭建好的平台进行阅读并充值,从而赚取分成,大概比例是80%…
-
移动视频监控(移动视频监控app叫什么)
前言大家好,我是林总,移动式视频监控系统是计算机、移动网络、视频编码技术及视频传送器的结合,它可以将不同地点的现场信息实时通过移动网络传送到监控管理中心和掌上设备。在被监控点,通常…
-
kvm切换器(kvm切换器是干什么用的)
公司电脑会因为资安考量,禁止安装诸如LINE 之类的软体,因此很多人会选择在手机上进行工作,但这可能会导致一个困扰。大部分的资料锁在公司电脑,工作必须频繁地在电脑与手机之间切换,过…
-
阿里云服务器价格表(阿里云服务器价格表2核8G_带宽4M)_
长期以来,阿里一直被认为是一家堪比华为的科技企业。阿里云和达摩院都被捧到了很高的位置,大家都认为阿里会成为继华为之后又一个伟大的科技企业。 但相比华为突破一个又一个技术难关的坚定步…
-
风暴云怎么形成的(风暴云是怎么形成的)_
世界上有什么神秘的力量吗?我相信很多人在某个特定的时刻都会这样的思考的,近期发生在重庆上空的神秘之事,让不少人又开始了这样的思考。 7月25日晚上,重庆上空突然出现了一个巨大的风暴…
-
锚点_拼音(锚读音是什么)
◎洁尘(作家) 对于斯德哥尔摩的记忆,两个锚点,一是诗人、翻译家许岚和她的家,还有就是许岚翻译的长篇小说《男人》。前者在斯德哥尔摩现场,后者在书里。 诗人、翻译家许岚是我的朋友,成…
-
qq监控(qq监控对方聊天记录)
手机被人整整监控十年了,甚至QQ都被这个变态偷盗了!也不知道这个变态想查什么呢?想起来真让人恶心的!这十年来她不只一次跟同学朋友聊天时骂监控变态的脏话,他不是欢窥私吗?喜不喜欢听脏…
-
邢台网络安全宣传系列第三十三讲巨鹿县“青少年网络素养实践教育基地”挂牌成立
为扎实推进网络文明建设,进一步增强青少年网络素养意识,拓宽网信宣传阵地,8月30日,巨鹿县委网信办、县文化广电和旅游局在县图书馆举办“巨鹿县青少年网络素养实践教育基地”揭牌仪式。 …