
前言
大家都知道基于微服务,特别是规模化微服务的系统,它存在着各种困难。其中有一个困难就是我们需要一套稳定的测试环境,但是在面对如此多的服务,而且还有很多第三方服务的情况下,我们如何才能得到一套稳定的环境,这是我们在测试和开发工作中面临的一个非常棘手的问题。其中有一个方案和技术就是服务虚拟化的技术,它可以很好地解决我们在规模化微服务项目中的测试环境的稳定性问题。今天我们就以这个话题来进行探讨。
我们今天的目录包括三部分:
第一部分:就是规模化微服务测试的现状和问题;
第二部分:是服务虚拟化架构创新和技术重点;
第三部分:是我在自己曾经完整交付的一个在线支付项目中如何去落地服务虚拟化的技术实践及总结;
最后:我们会把这些内容简单地总结一下,方便大家学习相应的知识。
一.规模化微服务测试的现状和问题
首先我们来看一下规模化微服务测试的现状与问题。现状大家都知道,问题其实是非常多的。我基本上在每一个刚刚启动的新项目上都会遇到各种测试环境不稳定的问题,其中很多就包括测试数据很难构造、Dependencies 经常不稳定、不管是它的版本在不断更新,或者因为它的网络环境、还是说它自身由于各种不确定性,造成的一会儿可以使用,一会儿不能使用等各种问题。
1. 测试环境被多个团队共同使用
这些问题我们归结成四类:第一类就是测试环境会被多个团队同时使用,当一个测试环境被多个团队同时使用的时候,他们关于测试环境、测试版本的需求都可能是不一样的,所以这个时候你如何让不同的人能拿到不同的测试数据以及相应的测试 API 的表现行为,这是一个很大的问题。
2. 测试数据的准备需要花费大量时间
第二个是测试数据的准备需要花费大量时间,很多特别是我们做银行系统的,它的很多子系统的交易数据是很难构造的。我去过不少银行,他们最大的一个痛点之一就是他们底层的交易数据以及底层的各种类交易数据,就是和交易数据相关的其他数据准备是非常困难的,这个时候就肯定是需要一套 Mock 系统,而这套 Mock 系统,如果你要人工去构造的话,它成本也是非常高的,因为它们有各种关联性也非常难以构造。
3. 某些服务的部署或网络等问题导致测试环境不稳定
第三个就是某些服务的部署和网络问题导致的测试环境不稳定,这可能是由于现在很多服务是构建在虚拟化网络上面的,比如说 Amazon 的这种网关、网络等各种搭建都是基于代码去配置的。所以这种时候不管是因为基础设施 Infrastructure 的代码出了问题,还是在升级,还是说有些时候就是网络的不稳定造成的,都可能导致你的某些服务不可用。那这时整个测试环境就崩掉了,就不能用了。
4. 依赖服务的版本更新影响了当前版本的测试
第四个就是依赖服务的版本更新影响了当前版本的测试。那就是说由于你的第三方版本,或者是你的内部开发的微服务的某个版本不小心升级了,或者是说它需要升级,这个时候你本身这个版本还是基于老版本的测试,你就很难解决你的问题,就很容易出现老版本和新兴版本不兼容的问题,导致你的测试环境不可用了。
所以主要是这四类问题。第一个问题就是测试环境被多个团队使用,同一个数据有可能被不同的团队修改,这个时候我们就需要数据的多样性以及数据的数量的多样,这样的话每个团队可以分。在很多时候一个环境是很难构造足够多的数据的,像我现在做的一个银行系统也是,数据的构造是非常复杂的,所以说构造数据量是有限的。很多时候是多个团队在用同一个数据,也就是同一个数据可能被其他团队占用,这个时候就很麻烦了。因为一旦占用了之后,理论上说我就不应该使用到,如果你去使用的话,会影响到别人,别人的测试也就会被影响到。
那测试数据的准备不要花大量时间,因为数据的关联很多,数据一旦使用就无法还原,特别是像比如最近我们使用的一个系统,它的 Source Token 一旦被注册了,它就不能再被注册了,这种就是非常痛苦的。
测试数据可能被刷新或者销毁,有人刷新、销毁你是无可预知的,某些服务的网络导致测试不稳定可能是有些情况比如依赖服务正在部署、依赖服务正在调试、依赖服务存在某个 bug 导致某个功能失效。这个时候你要么就等着它们部署好、等待它们调试、等待它们把 bug 修好,其实你的时间也浪费了,可能你的测试工作或者你自己的测试工作就会被 block 了。
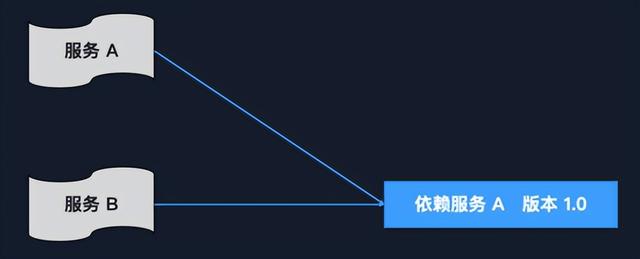

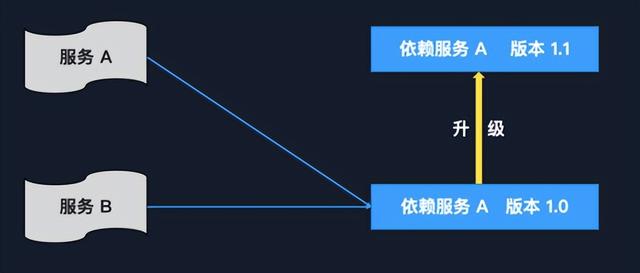
还有一种情况,最后一种问题就是依赖服务的版本更新。就是说我有两个服务,比如说现在一个依赖服务它是 1.0 版本,突然它版本升级到 1.1 了,这个时候你的服务 A 和服务 B 是没有办法依赖于这个版本 1.1 的,只能在 1.0 的版本上面工作。此时你肯定要进行更改、修复,这个时候如果你还没有来得及去兼容 1.1 的代码修改,服务 A 服务 B 的测试工作全部都得停止,银行就不能工作了,你必须等到你的开发人员把服务 A 和服务 B 的兼容 1.1 版本的工作给完成了才行。这个时间段内的测试工作,基本上就被停止了。
二.服务虚拟化的架构、创新和技术重点
这种情况下,我们如何能很好地在这段时间依然让服务 A 和服务 B 的测试工作正常进行,就需要有相应的解决方案了。这个解决方案其实就是服务虚拟化,在传统的服务虚拟化的解决方案里面,他们不叫服务虚拟化,叫 Stub 或者叫 Mock。
1. 传统 Stub 服务的架构
我一般叫 Stub,所谓的 Stub 服务,就是我有一个虚拟服务、有一个真实服务,其实被测系统要么全部用我的虚拟服务,要么就全部用我的真实服务,这就是最经典的 WireMock 最开始用的方案。
传统 Stub 服务的架构:
这种方案最大的问题就是它非常死板,传统的意义上来说,它要么就是全部使用依赖服务,要么全部使用真实服务,所以说它能解决一部分问题,但是它很难解决测试环境的多样性的问题。所以说在这种传统的 Stub 服务的架构上面,它其实可以解决上面我们提到的 4 种问题中的某些问题,但是它没办法很好地解决 4 种问题中的所有问题。
2. 服务虚拟化的架构和创新
服务虚拟化的架构和创新:
服务虚拟化对它进行了一个架构的创新,架构的创新是什么意思呢?其中最主要的理念就是我们要设立一套所谓的透明代理,而这透明代理的核心是说,当我去给我的被测服务提供所谓的 Stub 或者是 Mock,就是传统意义上的这种虚拟数据的时候,我并不是简单地只是提供虚拟数据,我还能提供各种自定义的虚拟数据,甚至是修改或是穿透。什么叫穿透呢?就是说我的数据可以是一部分真的、一部分假的,这个就是它最核心的创新的意义。
并且它还提供各种更新的理念,比如说它提供 RESTful API、提供 Docker 化,后面会慢慢地跟大家解答这些核心的技术细节点。提供这个之后我们可以更好地去适应基于云,比如说基于 Amazon、基于阿里云的这种云化的环境下面去部署所谓的虚拟数据和虚拟服务,这样的话更有利于现在这种大规模微服务的实施。不像以前的 WireMock,我可能就是单独起一个服务,可能还要起另外一种服务,这种方式非常传统,虽然可以解决问题,但是它解决问题的种类是有限的。
2.1 服务虚拟化的技术重点一 —— 录制
其中虚拟服务化的技术重点之一就是录制,录制是传统技术的基本上最理想的功能。不管是以前的 Stub、Mock,还是虚拟服务化都需要支持。所以说这是一个基础功能,因为有了录制,你才能节约很多人工去写数据的时间。
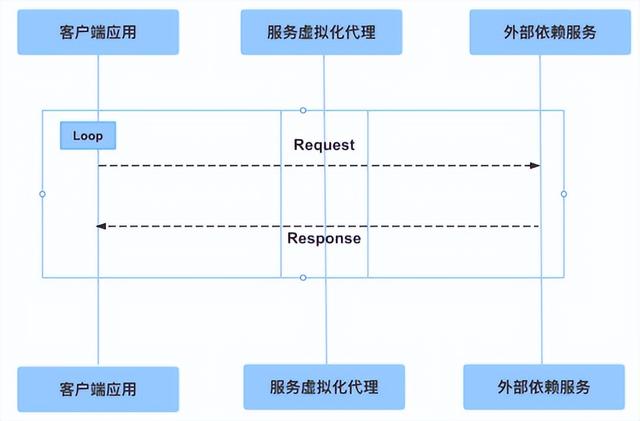
服务虚拟化的技术重点一 —— 录制
一旦你录制完了之后,你就可以把这个数据进行定制化,很容易地用起来,所以说它的理念就是它需要有一个代理服务器,当你的数据和你的真实的依赖服务进行通信的时候,它会在中间把你的数据录制下来。这个是很多的传统服务比如 Stub、Mock 或者是虚拟化服务的技术都需要有的基础功能。
2.2 服务虚拟化的技术重点二 —— 修改
第二个功能也是一个比较基础的功能 —— 修改。就是说我不是简单地把录制下的数据或者手写的数据放置在那儿,你去访问它,它就能返回一个你希望要的数据,并不是这么简单。而是说我可以提供第三方脚本来动态地根据不同的参数获取不同的数据。比如说我要获取当前的时间,如果你写死的一个 Stub 数据,你获取的永远都是固定时间;这个时候我其实有一个数据可以去获取当前系统的时间,然后返回时间。
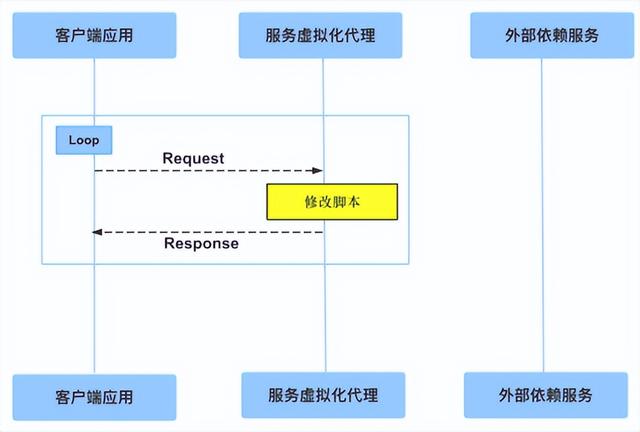
服务虚拟化的技术重点二 —— 修改
你可以把相应的修改脚本放在你的虚拟化服务器代理里面,当你获取 API 的时候,它就会自动地去调用系统时间。当然我还可以做各种其他的自定义,这个也是服务虚拟化的最重要的一个功能,很基础的功能。
2.3 服务虚拟化的技术重点三 —— 模拟穿透
其中它最有创新意义的一个功能 —— 模拟穿透。模拟穿透是什么意思?其实它最核心解决的问题就是到底应该用模拟号的假数据还是应该用真数据,这个不应该是以请求的 URL,或者是不应该与我的服务配置有关,它应该是和我的数据有关。假设三个用户登录:第一个用户登录,他应该拿到的所有的数据都是假数据;第二个用户登录,他可能拿到的全部都是真数据;或者说第三个用户,他登录的时候用的是真数据,但是里面某个功能用的是假数据,这些都是可以的。
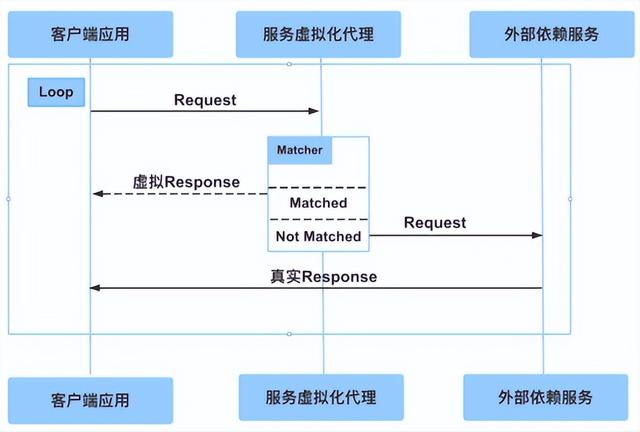
服务虚拟化的技术重点三 —— 模拟穿透
对于很多特定的微服务的功能测试,因为微服务是把很多服务分成各个小的这种领域服务,所以说某些服务不可用,可能导致某个功能就直接崩掉了,但是其他功能可能还可以用,这种时候我只需要虚拟化某一个服务的 Dependencies 就可以了。所以这种时候我可以根据我的定制化需求,只虚拟某一部分,或者只虚拟某一些特定的账号,这种时候就需要模拟穿透。
大家可以很明显地看出来,其实就是在虚拟代理服务器里面有一个所谓的 Matcher(匹配器),当我的匹配器规则满足某一个请求的时候,比如我的 HTTP 的 Header、或者 HTTP 的 Body、或者 HTTP 的 Parameter 都可以,Get Parameter 或者是 Post Body 中某一个 ID,它只要匹配到这个值时就用假的数据,如果没匹配到就直接去访问外部真实的依赖,返回真实的数据。这个是我在很多项目中用的最多的一种模型,非常实用。
2.4 服务虚拟化的技术重点四 —— 穿透修改
第四个重点就是穿透并修改,它其实就是在上一个穿透的功能上做了另外一种扩展,扩展什么意思呢?就是说我可以让你穿透,穿透之后我可以把这些穿透的数据根据我的一些规则进行修改,这个使用的场景不多。
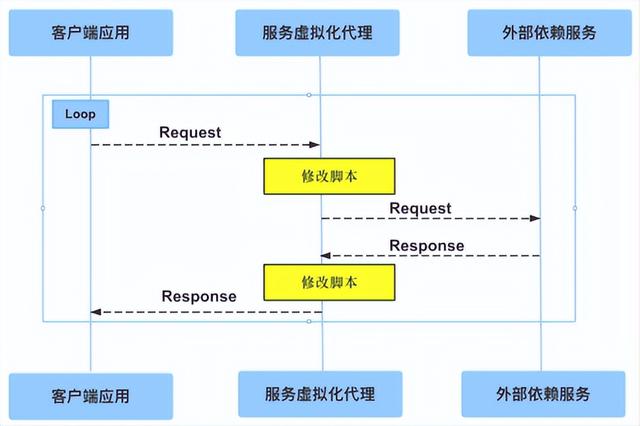
服务虚拟化的技术重点四 —— 穿透修改
但是有很特殊的一些场景,比如说我在做安全测试的时候,或者安全测试模拟的时候,大家可能听过 Man-in-the-middle attack,所谓的中间人攻击,这种时候它是可以很好地产生或者模拟一个中间人攻击的场景,所以说它也是非常有意义的,能解决我们很多很特殊的场景。
2.5 服务虚拟化的技术重点五 —— 差异化(Snapshot)
第五个是一个非常特殊的场景,这个也是很多服务虚拟化技术里面所使用到的,它其实就是用了一个所谓的 Snapshot Test 的概念,就是差异化,或者是叫对比测试。它的核心点就是我可以录制我上一个版本的微服务,比如说刚才我们遇到的第四个问题,就是微服务版本 1.0,这个时候当我的外部服务升级到 1.1 版本的时候,我去跑一下测试。跑测试的过程中,如果我的代理服务器里面存的是 1.0 的版本,但是访问的外部服务升级到了 1.1 版本。1.1 返回的版本和 1.0 版本如果有区别,代理服务器就会报警、报错,就会告诉你,其实现在你拿到的 Response 外部服务已经变成了新的版本,而不是老的。
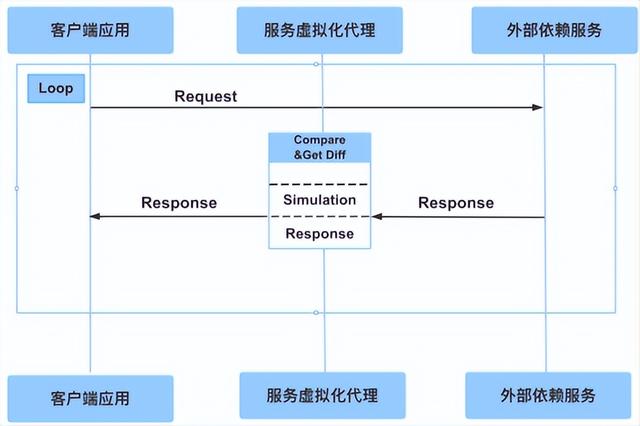
服务虚拟化的技术重点五 —— 差异化(Snapshot)
这个时候你就可以用它完成类似于像 Schema Test,我们所谓的外部依赖的 Schema 的结构测试,或者 Snapshot,就是差异化测试。这样的话可以省去你很多工作量,它可以很好地侦测到你的服务有没有变化,当服务有变化的时候,其实可以自动化启动你的版本功能,就是我们之前说的让它维持在 1.0 版本,这样的话 1.0 所有的服务就可以动态地去启动起来,而不是去使用 1.1 版本的。所以差异化服务给了我们更多的想象空间和操作空间。
3. 服务虚拟化的技术重点总结
服务虚拟化技术的重点我们总结一下。服务虚拟化是可扩展的,不管是刚才我们看到的穿透还是定制化,它其实都是修改模型,都是可以定制、可以扩展的。我们把传统的基于这种 Stub、Mock 的服务,可以随便地去扩展新的功能,而不是简单地返回一个固定的数据,然后我们还可以提供 RESTful API,很容易地去控制它,这样的话我们就可以通过编程的方式来控制我的虚拟化服务器的代理了。
第二个是虚拟服务可以定制化,什么叫定制化呢?就是我可以根据我的需求来定制化我的功能,它和可扩展性的意义类似,只不过可扩展性体现的是我可以扩展,而定制化是我扩展的过程中还可以通过代码,比如说 Modify 模型,其实是嵌入了一段基于 Python 或者 Java 的代码,这样的话我可以在我的修改里面自己写代码去实现我的功能,这是可定制化。
可配置化也是一个非常重要的功能,它的配置我们是可以通过 RESTful API 去远程配置的,而不是简单的,一旦我运行起来所有的配置是不可变的、所有的功能都是定好了,只能通过命令行去操作,或者通过本地的方式操作,而不通过语言的方式去操作,为什么要这样呢?因为现在很多时候虚拟服务器是部署在云端的,云端的时候,其实我需要通过 Jenkins 去控制它,而不是人工地去调试它。很多时候我通过 Jenkins 触发一个功能,就能在特定的情况下去配置虚拟化服务器,达到一个特定的状态,比如说 1.0 还是 1.1。或者是说当我 Snapshot 测试挂的时候,或者什么测试挂的时候,我能把服务切到某个特定版本,所以说需要远程可配置化。
还有可容器化,可容器化也是一个非常重要的功能,因为现在很多服务都是基于云的,它都是容器化的解决方案。所以如果容器化了之后,就很容易地可以在云端进行部署了。
另外就是支持双向证书。支持双向证书的话,如果懂 HTTPS 和 SSL 的人就知道,因为有些服务和服务之间的通信用 HTTPS,它可以要求客户端支持 Pinning,所谓的 Pinning 就是客户端的证书,如果不是和服务器端证书是匹配的,其实客户端发的请求,服务端是可以抛弃的、不认的。服务器端证书就是服务端需要有个证书,客户端必须要去认可这个证书,不认可的话,那客户端也是可以把它扔掉的,大家可以想象这个代理服务器在中间,如果我的证书不是双向的,就是不支持双向的,这样的话有可能只是在某一端我支持了。
比如说现在 WireMock 就不支持客户端证书,什么意思呢?假设你用 WireMock 架在服务 A 和服务 B 中间,并且服务 A 和服务 B 都是 HTTPS 通信,支持 SSL Pinning 的,这个时候如果你的 WireMock 没有办法把 B 服务的 Client 证书集成进来,所有的通过 A 服务发的 WireMock 再转发到 B 服务的请求,都会被 B 服务禁止掉,因为 WireMock 没有办法支持 Client 证书。其实服务虚拟化就需要支持这个,因为现在很多微服务,特别是规模化微服务里面都需要支持这个功能。
三.一个在线支付项目的落地实践
这是我的一个真实的在线项目的落地实践。这个实践里面其实是一个抽象出来的项目,现实其实远比这个复杂,比如说它的领域服务有银行服务、存储服务、第三方的认证服务等等很多服务,我只是把它抽象成了领域服务 1、2、3、4、5、6。因为我们落地实践的时候,用的中间代理是 Hoverfly(我在文章里和演讲中都讲过很多),那么我就详细讲讲 Hoverfly 的本质,也就是它本身的特点。
1. 架构
架构:
我们是基于 Hoverfly Proxy Server 来搭的一个所谓的虚拟化服务 Server。大家可以看到这里面画了 1 个我们的被测服务,但其实被测服务是很多的,至少是 10 个以上,这 10 个以上的被测服务都会同时连到 1 个 Hoverfly Server。1 个 Hoverfly Server 也可以同时连到十几二十个不同的领域 Server,其实这些领域 Server 和被测服务之间本质上来讲可以是我们开发的服务,也可以是云服务,也可以是第三方的 Dependencies 服务,这个不是重点。
重点是说 Hoverfly 可以架在我们自己开发的领域服务和领域服务之间,也可以架在我们的领域服务和被测依赖服务之间。所以说大家看到我用了不同的颜色,其中最下面 5 和 6 就是两个所谓的 Dependencies 服务。前面两个和我们是相同的颜色,就是我们自己开发的领域服务。因为我测试的时候肯定是基于某个特定的功能来测某个特定的 API,所以这个示意图只是示意这个被测服务我可以通过手动 API 去测试,也可以通过 CI 上的自动化测试来进行测试。
2. 实践重点
基于这种架构来看一下我们是如何去做实践的,这个实践的重点是什么。我把实践重点列成了很多小条,因为大家可以很容易进行总结。首先我们选择了虚拟服务化工具 Hoverfly,选择 Hoverfly 最主要是因为它的性能很好,后面我们会说还要来做性能测试挡板,这是其中一个特点。第二个特点是它支持双向证书,也是后面会详细解释的。还有最主要的是它能几乎全部支持刚才我上面提到的那些模型,不管是穿透模型、录制、修改模型,还是 Snapshot 模型都有,所以说我能很好地进行一个扩展和定制化的工作。
第二我们要选择真实的服务来录制生成虚拟数据,一般来讲我的数据全部是录制之后,再经过第二次加工修改来生成的,所以我们的录制工作也是非常重要的。
第三我主要的测试工作全部是基于模拟穿透模型来的,就是说只要把需要的虚拟数据导入到 Hoverfly 里面,这些数据匹配上后,它就会返回这些虚拟数据;但是一旦没有匹配上这些虚拟数据,它就会访问真实数据。这是一个我用的最多的功能,在这个项目上 90% 以上的虚拟数据都是通过这种方式来提供的,还有其他一些别的方式来提供的。
因为大家可以知道 Hoverfly 是可以通过 RESTful API 来远程配置的,所以说我会随时切换不同的模型,选用容器化的方式,在 AWS 上部署 Hoverfly。
因为我们整个系统是架在 Cloud 上的,所以说我们利用了 AWS 的 Docker 的方式来部署 Hoverfly。Hoverfly 在 Docker Hub 上有自己的标准,官方提供的 Docker 的镜像。我们也可以自己去做,还是非常容易的,因为它就是一个基于 Linux 的二进制包,很容易搭建起来。下面我们选用了 Hoverfly 自己提供的 RESTful API,来控制和配置虚拟服务。就像我刚才说的,我可以通过 API 来导入虚拟数据,我可以拿来切换模型、切换功能,什么时候我应该切换到什么模型,什么时候进行什么都会完全根据我要跑什么测试来手动切换的。下面我们还使用到 CI 流水线来发布和启动虚拟服务,也就是说这一切我都不应该手动去做,包括发布虚拟服务、导入数据、启动服务都是通过 Jenkins,用 CI 的流水线来做的。
接下来我们还使用到真实的测试数据,这是我的一个测试策略。使用真实的测试数据来对 API 进行小规模的集成测试,因为我们不可能把所有的 API 测试都用模拟数据来进行返回,我们其实也是构建了一部分的真实数据。因为在我们可行的范围之内构建了足够多的真实数据,这部分真实数据对应的 API 测试,全部是跑真实数据的,所以说我们的自动化测试里面会有一部分测试跑的账号是真实账号。真实账号里面就会扩真实的 Dependencies,但是因为我们的测试场景是非常多的,大规模的回归测试是会基于伪造的虚拟数据进行,所以说我们会在测试数据的分类里面有两部分数据,一部分是真实数据,一部分就是我的虚拟的伪造数据。这些不同的账号、不同的数据就会存成不同的文件,跑测试的时候就对应着不同的测试场景。
我们还使用到了伪造数据来模拟错误注入,什么意思呢?大家可以想象一下,就是说我们假设想模拟领域服务、领域 API,服务 API 1 在失败的情况下,被测服务应该是什么样的状况呢?这个时候如果有了 Hoverfly,你就可以很容易地把领域 API 1 的某几个账号对应的数据让它返回特定的 504、500 或是 400,也可以是超时 timeout。你都可以去模拟这些特定的失败,模拟特定失败之后,再看一下被测服务 A 的 API 的自动化测试或手动测试有什么样的表现。
这样的话就是完成了一个基础的错误注入测试,其实错误注入测试大家都知道,这是混沌工程的一个最核心的能力。混沌工程里面最核心的能力就是我能进行错误注入,并且根据错误注入之后可以动态收集整个系统的情况,然后去调试、分析、优化。混沌工程其实是一个很复杂的工程,但是它核心中的核心就是,我们怎么实施动态的错误注入。错误注入通过 Hoverfly 其实可以很容易地手动实施,此时你可以实施一个比较简易版的手动混沌工程,这是我个人总结的。
在银行项目里面大家可以知道,假设我的银行 API 交易超时了,我去调真正的银行的 API,而银行的 API 是银行提供给我们的一个测试服务,它不会返回一些特定的 error,不可能给我们提供 error,所以这个时候像 timeout、500 的报错,我怎么让我们的服务去获得银行服务的 500、timeout 或者 400 情况呢?只能是通过 Hoverfly 来模拟了。
当我们做性能测试的时候,因为银行服务中就算是测试环境,也是有限制的,就是固定时间内只能调用多少次,所以说基本上不可能用它来连接真实的银行服务做性能测试。这个时候我就选用了 Hoverfly 来做性能测试挡板,大家知道 Hoverfly 是用 Golang 写的,所以它相对于 WireMock 来讲,性能非常高。当我的性能测试不断提升的时候,其实我能保证我的性能测试挡板的性能一定要比我被测系统好;如果反之,我的性能测试挡板的性能比我的被测系统要差,这样的话我测的不是被测系统的性能,而且性能挡板的性能,所以说用 Golang 可以很好地解决性能测试挡板的性能问题。
这样的话,其实我测出来的性能基本上可以认为是我被测系统的性能,而被测系统我们是用 Java 写的,也分析过它的性能,一般来讲都是比 Golang 要差很多的, 可能很多人会诟病 Java 写的这一点,从我现在测出来的结果看它确实要差一点。最后我们是使用了支持服务端和客户端的双证书,因为银行那边使用 HTTPS,也是开启了 SSL Pinning 的这种功能,所以说最后我们使用了这个东西才能完整地模拟整个银行服务,包括需要的稳定性。
3.CI 流水线中的虚拟服务
CI 流水线中的虚拟服务:
我们再看看 CI 流水线中的虚拟化服务是怎么进行同步的?大家可以看到包括我首先录制并编辑 Simulation,就是我的虚拟服务的数据,这个时候我把它提到代码库里面,通过 code commit 提供到 Git Repo 里面,而 Git Repo 里面 Jenkins 流水线,你可以人工触发也可以定时触发,也可以在代码提交之后,通过一个 Hook 去触发 Jenkins API 调它的 RESTful API,Jenkins 自己也有一套 API 去触发流水线,流水线一旦触发,它就会把 Simulation 从代码库里面下载下来,通过 RESTful API 上传到 Hoverfly 并且导入到 Hoverfly 上面去,这是一个标准的服务。
四.总结
最后我们再总结一下今天我们讲的这个课程,我们讲到了一些服务虚拟化的基本功能、核心功能以及创新的点,包括它相对于 WireMock、相对于传统的 Stub 服务,它提供了一些新的东西,其中它主要是为了解决我们微服务测试中的几个最大的问题,包括测试数据和测试服务稳定性,它都能很好地通过不管是录制、修改还是穿透等各种方式来完成测试数据的多样性,包括稳定性也都能解决到。通过虚拟化服务可以极大地改善测试数据和稳定性,这个也是我们可以去解决的,通过 Hoverfly 的虚拟化服务,我们基本上解决了遇到的各种问题。
第三点,服务虚拟化的特点是功能强大,包括可定制化、可扩展化、远程配置化和 Docker 化。所以说我们需要有一套功能足够强大的虚拟化服务解决方案来实施以满足这些功能,实施我们的虚拟服务化,包括满足包括我们所说的所有功能。
最后,我的真实项目里面使用了一款 Hoverfly 的免费的,功能强大的虚拟化服务解决方案来解决,这个大家可以从我总结的几点里面知道我到底做了些什么,包括我们通过 Docker 化部署,通过 Jenkins 触发、上传、变更,Hoverfly 的这种模型,数据的管理,包括我们通过什么样的数据测试什么样的功能,还有通过证书来解决 SSL Pinning 的问题。
这就是我今天的一个简单分享,希望当你遇到测试环境不稳定、测试数据相关的一些问题,特别是在大规模微服务项目里面,能尝试一下服务虚拟化的解决方案。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/15969.html
相关推荐
-
智能人工客服系统(智能人工客服公司排行)
目前手机的应用太普遍了,几乎人手一部。确实给人的日常生活带来极大的方便。但凡事都有例外,那些不会使用智能手机的人,不仅享受不到它提供的好处,反而处处受到制约。 一天在公交车上,上来…
-
戴拿奥特曼(戴拿奥特曼飞鸟信扮演者怎么了)
北冰洋近400岁的格陵兰鲨,它从1627年就开始在海洋中游荡,是世界上最长寿的脊椎动物,其长寿的原因是:1.极地冰冷的海水让它的新陈代谢变慢,大约150年才发育成熟,平时游泳速度每…
-
速云车联app安卓下载,速云车联
不知道什么时候开始”内卷“”画饼“等词活跃于网络和职场人的嘴里,“画饼”这个词更是被人熟知,它常用于职场中“老板画的饼”“公司画的饼”……所谓”画饼“,就是…
-
阿里云电话95187是什么(阿里云电话人工服务)
电话客服现场管理制度 一.现场工作制度 1.工作人员进入现场应保持安静,不准在现场内闲聊、喧哗。 2.员工进入工作场所应精神饱满,注意力集中,坐姿端正,不做与工作无关的事,不擅自离…
-
钉钉企业版收费标准(学校钉钉企业版收费标准)
在企服赛道已变成红海的今天,我们看到许多办公软件推出了各式各样所谓人性化体验的功能,但那真的是办公族们所需要的吗? 我们看到很多影视作品探讨着科技与人之间的关系,最近在著名电影导演…
-
拜访地接入怎么开通(联通拜访地接入怎么开通)
摘要 认证是移动通信系统的重要安全手段,主要用于鉴别功能实体的身份的合法性。为满足企业/行业用户远程移动业务应用的需求,依托移动运营商网络构建专网已成为业界的主流方式。目前业界认证…
-
百度云_试用(百度云试用加速的触发机制)
今天早上我遇到一个大问题,就是终于找到了我最喜欢的电影资源,但是就在保存的时候出事了:空间容量不够!接着我就只能发动我聪明的小脑袋瓜,在网上开启了一大轮的寻找,最终终于让我找到了,…
-
电信天翼云待遇怎么样(电信天翼云盘有什么用)
6月13日,由中国信通院、中国通信标准化协会主办的“数字政府智创沙龙”在线上举办。天翼云凭借丰富的资源与实践经验,顺利通过信通院数字政府-智慧中台评估。 天翼云高级解决方案架构师黄…
-
什么是磁盘(什么是磁盘空间不足)
笔记本电脑主要用来处理文档,设计等。很多用户在使用笔记本电脑时,都会遇到笔记本硬盘损坏的情况。如果电脑故障了,一般情况下我们都会第一时间把它打开维修更换机械硬盘。但很多人不知道…
-
免费国外空间资源(免费国外空间资源网站)_
近两年裸眼3d非常流行,主要应用于直角幕、L幕以及CAVE四折幕等 , 但是制作片源很麻烦,不仅要做创意,还要做摄像机校正和反渲。 针对这一难题,我们开发了一套裸眼3d软jian或…