
自顶向下的迁移方案
借鉴某位前辈的总结:


为什么上云
除了大环境和行业发展浪潮推动业务上云,还有更实在的原因,比如老板决定了要迁移上云、拥抱云,除此之外在技术上还有一些原因:
最佳实践
– 蚂蚁搬家式迁移,迁移不可一蹴而就;
– 通过混合云架构实现平滑迁移。
迁移上云的步骤
从项目视角来看,迁移可以用“观云、迁云、享云”三步走来实现:
- 掌握云平台及业务自身情况做好迁移前的准备。
- 通过实施、测试、演练和割接完成整个迁移过程。
- 最终可以享受云平台带来的便利和稳定。
具体操作步骤分为这几个阶段:
- 准备阶段
- 实施阶段
- 测试阶段
- 演练阶段
- 割接阶段
- 验证阶段
技术视角
从技术视角来看,业务迁移上云包括主机迁移、数据迁移、流量迁移,如果采用了大数据、人工智能等业务则准备相应模块的内容即可,本文选取最基本的三块来介绍。
主机迁移
业务系统的应用层、逻辑层运行在主机上,该怎么迁移?
- 主机数量少:完全可以在云端创建相同数量的云主机,然后安装Apache、Tomcat或者IIS,在云端安装相同的软件、运行同样的代码,构建与本地环境一模一样的业务。
- 主机数量多:我们可以选择通过制作镜像的方式进行迁移,即将运行业务的主机整体打包制作为镜像,然后复制镜像到云端并导入到云主机中,云主机启动后即可拥有相同的业务能力,避免了繁琐的手动安装环境的过程。
除了镜像迁移的方式,还可以通过底层文件同步的方式实现主机迁移。主机上的软件、代码、数据还是落在硬盘上,在本地硬盘和云端硬盘之间进行底层文件复制的方式完成主机迁移,在云端云主机挂在已经存有软件、代码和数据的硬盘可以恢复主机的业务能力。
数据迁移
业务系统除了应用层、逻辑层代码,还有数据。我们可以根据数据的类型采取针对性的迁移方案。面向结构化数据,也就是MySQL等关系型数据库,可以采用云平台提供的数据迁移服务UDTS工具来迁移。
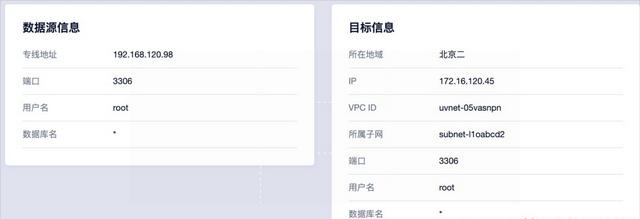
UDTS支持将自建MySQL数据库迁移至云端数据库,接着开启增量迁移将新增的数据持续同步至云端数据库,最终达到本地和云端数据一致的情况,完成MySQL数据库迁移,可将对数据库的连接从本地更改到云端。
静态数据迁移
业务中海量的图片、视频、PDF、CSS等各种静态文件需要进行迁移,无论存储在本地环境还是其他公有云平台,都可以通过设置资源回源的方式完成资源迁移。这种方式牺牲了第一次访问该资源的相应时间,通过第一次的拉取为后续访问带来了便利。如果有少数资源从来没有被访问到,则还是仅存储在源站,这时可维护一个未回源的资源列表并触发程序去模拟访问资源完成回源访问,最终完成所有静态资源的迁移。
优点:静态资源通过回源的方式进行迁移,不会影响业务的使用,业务无需中断,没有额外的费用成本。
缺点:不过时间周期较长,不适合数量众多、超大文件的迁移。
- 迁移工具
UCloud云平台提供有对象存储迁移工具ufile-import,将工具部署在本地环境或其他云平台中,即可将数据迁移至UCloud对象存储UFile中。
流量迁移
业务和数据都迁移完成后,还需要将用户请求从本地环境切换到云端,也就是常说的割接。至少有三种方式实现切换:
- 直接切换,为业务设置一个维护时间,比如业务请求量低的凌晨进行流量切换,业务需要中断;
- 并行切换,通过混合云的实行实现平滑迁移上云,在一段时间内本地环境和云端按照不同的流量比例共同运行,也就是实现业务双活,然后逐步移除本地环境的流量,最终将所有流量切换到云端完成迁移;
- 分段切换,按照不同项目的不同阶段进行切换,选择容易实现的方式进行上云并验证,逐步实现所有业务完成上云。
内容源自《云端架构》作者吕昭波



使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/6288.html
相关推荐
-
应用监控页面展现内容包括(应用监控页面展现内容包括哪些)
在企业信息化建设的过程中,软件、数据库等各个组成部分的稳定性与故障率都与企业的生存与发展息息相关。但近年来,随着系统间数据交互及运行环境复杂性的增加,越来越多业务源端的软件问题所导…
-
应用程序无法正常启动0xc000007b(应用程序无法正常启动0xc000007b怎么解决)
大家好,我是阿萨。 如果你让应用开发者说出用户不再使用应用的一个原因,他们可能会将答案局限于一般的用户体验、应用推广和应用设计。虽然感觉这些都是正确的答案,但实际上,它们都是错误的…
-
ID4售后(ID4售后电话)
前阵子id4的左后阅读灯出了故障,总是忽亮忽暗,之前发了视频,相信好多朋友都看到了,后来来我们本地的售后来看过,并且订了配件,配件后来到了,只是我今天才腾出时间来换,其实就是把这个…
-
怎样注册网站免费注册(免费注册网页163)
限时免费注册哦~朋友们! 那么,有人要问,神彩企业环保服务平台是什么呢? 且听我说… 神彩企业环保服务平台是一个依照国家最新法律法规要求,为帮助企业实现EHS管理规范化…
-
路由器怎么升级(路由器怎么升级新版本)
很多情况我们的宽带网络、光猫、路由器都是千兆,但一些你可能忽视的细节,却大大限制了网络速度和信号强度,是什么原因?? 不久前把移动宽带升级到了千兆,并且从京东购入了2000多元的T…
-
中视酒水供应链商城(中视酒水供应链商城真假)
小蜜蜂供应链简介 园林行业数字化加速 小蜜蜂供应链成立于2019年8月,总部位于上海,由园林老兵丁强生先生创立,面向园林行业管理人员、项目人员、采购人员等提供线上一站式采购服务。平…
-
家庭组网(家庭组网最好的方案)
接触过软路由,了解过软路由系统的同学也肯定会听说过旁路由,辅路由,那这个旁路由(辅路由)究竟是怎么样的,又是如何工作的,想必刚接触的时候也肯定是一头雾水,今天这里,讲给大家详细解答…
-
阿里巴巴论坛首页(阿里巴巴论坛首页官网)
· 这是第4639篇原创首发文章字数 8k+ · · 秦朔 | 文 关注秦朔朋友圈 ID:qspyq2015 · 前言 阿里巴巴今晚公布了2023财年第一季度(2022年4-6月)…
-
rtu(rtu遥测终端机)
华世智能HS-6321/RTU适用于:环境监测仪,如:对光伏电站运行环境的温湿度、大气压、雨量、风速风量、电能计量、地质灾害、滑坡、泥石流、地表位移、水浸/水淹、光照度、储能电池的…
-
密云招聘(密云二手房出售最新消息)_
2022.6.11 (一)一个跌宕起伏的小型映画会 带俩崽子去图书馆还书借书,偶遇图书馆有小型映画会~ 刚到儿童书区,就有个带工牌的老爷爷过来说了个啥(老母亲也没听清),再后来…