
内部连结是指向(目标)与连结所在的网址(来源)皆是相同网址,简单的说,内部连结就是同一网站的另一个网页。
程式范例
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
最佳格式
在连结文字中使用描述性的关键字,以便了解来源网页,有尝试说明主题或关键字。
什么是内部连结?
内部连结是从一个网址的一个网页连接到同一个网址上的不同网页的连结,它们最常用于主选单上。
这些类型的连结分别为三种原因:
- 他们允许访客在网站内浏览。
- 他们用来帮助网站建立讯息的层级。
- 他们帮助传递网站权重(排名权)保留在网站内。
SEO的最佳做法
对于建立网站架构和传递连结权重来说,内部连结是最有用的(对外连结也是不可少的),以这个因素来说,要建立一个SEO友善的网站,网站架构与内部连结是很重要的。
在一个独立的网页上,搜寻引擎需要查看网页内容,以方便在大量的关键字索引中,列出结果网页,他们还需要访问可抓取的连结结构(一种让蜘蛛浏览网站路径的结构)以查询网站上的所有网页,(要查看您网站的连结结构,请尝试通过Open Site Explorer执行您的网站),成千上万的网站以搜寻引擎无法访问的方式隐藏或掩盖其主要导览连结,这是个严重错误,这阻碍搜寻蜘蛛将网页列入搜寻引擎索引的能力,下面是如何解决这个问题的范例:


在上面的例子中,Google的蜘蛛已经到达网页“A”,并且看到网页“B”和“E”的内部连结,不过C和D可能是网站的重要网页,但是蜘蛛没有办法到达那里,甚至虽然知道他们存在,但是因为没有可供抓取的连结,所以无法前往这些网页,就Google而言,这些网页基本上就代表不存在,如果蜘蛛无法到达这些网页,那么有再好的内容、再好的关键字SEO,与再聪明的行销策略是完全没有意义的。
一个网站的最佳结构看起来类似于一个金字塔(顶部的大点是首页):
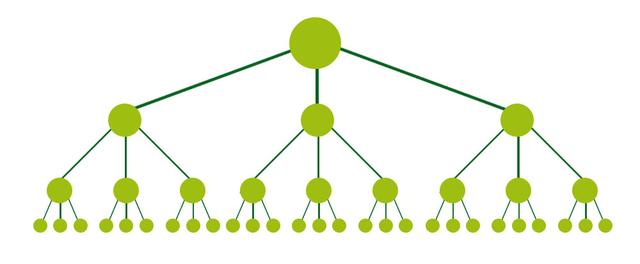
该结构在首页和任何特定网页之间,如果是最小可能的连结次数,这对SEO是有帮助的,因为它允许连结权重(排名能力)经过整个网站,进而增加了每个网页的排名潜力,这种结构在许多高性能网站(如Amazon.com)上以类别和子类别系统的形式很常见。
但是这是如何完成的呢?最好的方法是使用内部连结和补充URL结构,例如,他们在内部连结到位于http://www.example.com/mammals的页面,并带有文字“cats”的连结,以下是格式正确的内部连结格式,想像一下这个连结在网址名称www.newscan.com.tw上。

在上图中,“a”标签指示连结的开始,连结标签可以包含图片,文字或其他对象,所有这些都可以在网页上提供一个“可以点击的”区域,访客可以通过该区域移动到另一个网页,这就是网际网路的原始概念:“超连结”,连结引用位置告诉浏览器和搜寻引擎连结指向的地方,在这个例子中,引用了URL https://www.newscan.com.tw,接下来,访问者连结的可见部分在SEO世界中被称为“锚点文字”,描述连结指向的网页,在这个例子中,指向的网页是关于新视野网页设计公司的网页设计商品,因此连结使用锚点文字为“新野网页设计公司”,</a>标签会关闭连结,以防止标签后的其它元素不会将连结属性套用到它们。
对于搜寻引擎来说「连结」是一种很显著可以理解的基本规则,搜寻引擎蜘蛛他们大部分会将这个连结添加到网站的引擎连结图中,用它来计算查询独立变数(如MozRank),并按照它来索引并且引用网页的内容。
以下是网页可能无法被访问到的常见原因,可能因此而无法被索引。
表格栏位下方的“送出“连结
表单可以包含基本的元素,如下拉选单或像完整的问券调查那样复杂的元素,无论哪种情况,搜寻蜘蛛都不会去尝试“送出”表单,因此通过表单可以访问的任何内容或连结对引擎而言都是看不见的。
无法透过网站“搜寻栏位“建立索引
蜘蛛不会尝试执行搜寻来查找内容,因此估计数百万的网页隐藏在完全无法访问的内部搜寻栏位的背后。
无法解析的Javascript中的连结
使用JavaScript建置的连结有可能不好的,是有可能大大降低网页的呈现机会,不过似乎Google似乎已经克付了这个问题。
Flash,Java或其他UI中的连结
连结引擎通常无法访问嵌入在Flash,Java小程序和其他UI中的任何连结。
连结指向由Meta Robots Tag或Robots.txt阻止的页面
Meta Robots标签和robots.txt文件都允许网站所有者限制蜘蛛对网页的访问。
同一个网页上具有数百或数千个连结
搜寻引擎都有一个基本的抓取限制,每页150个连结,之后他们可能会停止从原始网页连结到其他的网页,这个限制是有一定的灵活性的,特别重要的网页可能会有200甚至250个连结,但是在一般情况下,将页面上的连结数量限制在150以内较为恰当。
Frames或是IFrames内的连结
在技术上,两个Frames和IFrames中的连结都是可以抓取的,但是从架构和追踪两个层面来看,这两种Frames都呈现结构性问题,只有具有高技术的工程师才能使用这些元素结合内部连结来让搜寻引擎索引和连结。
避免了这些陷阱,网站管理员可以有干净,可以让蜘蛛抓取的HTML连结,允许蜘蛛轻松访问他们的网页内容,连结可以应用其他属性,除了rel = "Nofollow "标签之外,引擎几乎忽略所有其他属性。
想快速浏览一下您的网站的索引?,可以使用「Open Site Explorer」「Screaming Frog」 来抓取你的网站,然后比较您在Google上执行网站搜寻时抓取的网页数量与列出的网页数量。
rel = "nofollow "可以使用以下语法:
<a href="/" rel="nofollow">nofollow this link</a>
在这个例子中,通过将rel = "nofollow "属性添加到连结标签,网站管理员告诉搜寻引擎,他们不希望这个连结被解释为正常的权重传递,“群众投票”,Nofollow是用来阻止自动部落格讨论,留言版和连结导入垃圾邮件的方法,但随着时间的推移,这种方法已经演变成告诉引擎,需要削弱通过连结权重的方式,但是每个引擎对于nofollow标签的连结都有些微不同解释。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/19594.html
相关推荐
-
滑动验证码测试网站(滑动验证码测试app)
#本文为人人都是产品经理《原创激励计划》出品。 登录或者注册一个新账号时,会有短信验证码提示;在社交平台点赞评论时,会有拼图验证码提示;在抢票的关键时刻,跳出个辨认红绿灯的验证码提…
-
轻量http服务器,SpringCloud 微服务架构理论入门
1、微服务架构的演变 1.1、单体应用架构–单数据库多应用服务架构 互联网早期,一般的网站应用流量较小,只需一个应用,将所有功能代码都部署在一起就可以,这样可以减少开发…
-
中台运营职责(运营是中台吗)
张妍怎么都不会想到,一波突如其来的疫情,会让自己无法按计划将儿子小帆在开学前,从安徽阜阳老家接回海南三亚就读新学期。 正当全家为此一筹莫展之时,一个念头从张妍和家人的脑海里闪过——…
-
自组网(自组网通信技术)
公园作为大家平常放松娱乐的场所,人流量大,树林、湖泊、假山等布局密集,环境复杂且存在较多监控盲点死角,其安全问题不容小觑。为了做好安全管理,在公园的出入口以及活动场所进行监控,但问…
-
电脑控制软件(远程电脑控制软件)
马上又到了家里圣兽放假的时间了,为了家里神兽避免一天坐在电脑屏幕前打游戏,所以给大家推荐一款电脑上网控制软件,大小40KB,简单实用,下载到电脑后不需要安装直接右键点以管理员运行,…
-
甜蜜蜜高清手机在线观看(甜蜜蜜高清手机在线观看免费)
华强北做二手有锁机的“明哥”给分销商一批机器,分销商到手之后发现机器情况不对,除了运营商锁之外,还有一个配置锁,而还不是例外,这一批货全部都是运营商商锁+配置监管锁,这样每一台机器…
-
服务器租用试用(服务器试用)
我们上网所浏览的网站,电脑上面的应用程序,包括手机上的APP,微信的小程序,玩游戏加载进入的游戏内容都是由服务器所搭建的,也就是说,虽然很多人都不知道服务器是什么东西,到底应该怎样…
-
免费全能主机,全能一体机
当下各大商业中心火爆的“共享主机游戏机”项目正受到广大年轻人的追捧,我们也怀着强烈的好奇心对市场进行了一次调研。通过调研我们发现,目前市场上的共享主机游戏机实际构成并不复杂,内部构…
-
价签打印(价签打印app下载)
长江日报大武汉客户端8月11日讯(见习记者樊友寒)8月8日,记者发现多名网友在社交平台反映,江汉路上的网红怀旧零食店未明码标价,记者前往探访发现网友所说属实。10日下午,长江日报记…