
前言
很多开发人员都知道索引对于数据库的查询性能至关重要,一个好的索引能使数据库的性能提升成千上万倍。但给数据库加索引是一项相对专业的工作,需要对数据库的运行原理有一定了解。同时,加了索引有没有性能提升、性能提升了多少,这些都是加索引前就想知道的。这项繁杂的工作有没有更好的方案呢?有!就是今天重磅推出的索引推荐。
索引推荐这项技术概括起来就是通过分析SQL,枚举可能的索引组合,并通过优化器What-If的能力,选出其中收益最高的索引组合推荐给用户。索引推荐可以极大降低用户的使用门槛,增加数据库智能化能力。RDS PostgreSQL在新版本中已经自带索引推荐功能,可以通过访问PostgreSQL数据库亦或通过RDS控制台使用索引推荐功能。
技术原理
1、索引推荐流程
1、分析 Indexable Column,分析出SQL中哪些列可以利用索引,例如:
- Where条件中的 =, >, <, between, in等列
- Order By的排序列
- Group By的聚合列
- MIN,MAX函数列
- Join的Condition列
2、构建 Candidate Index
- 从IndexableColumn中构建出所有可能的Candidate Index
- Candidate Index分为单列索引和联合索引,单列索引包括所有Indexable Column,联合索引以一定规则组合Indexable Column
3、优化器What-If选择最优
2、优化器What-if能力
G查询优化是基于代价的,分为启动代价,运行代价,总代价,计算方式为{CPU cost + IO cost}。
- 启动代价:读取到第一条元组前花费的代价,比如索引扫描节点的启动代价就是读取目标表的索引页,获取到第一个元组的代价。
- 运行代价:获取全部元组的代价。
- 总代价:二者之和。
索引的代价计算是由固定公式得来,只要构造索引时补充公式需要的变量,就可以利用到优化器的What-If能力。
方案实现
1、总体流程
1、采用通用的索引推荐流程,注册planner_hook,遍历查询树,构造索引项,依赖优化器的What-If能力得到结果。
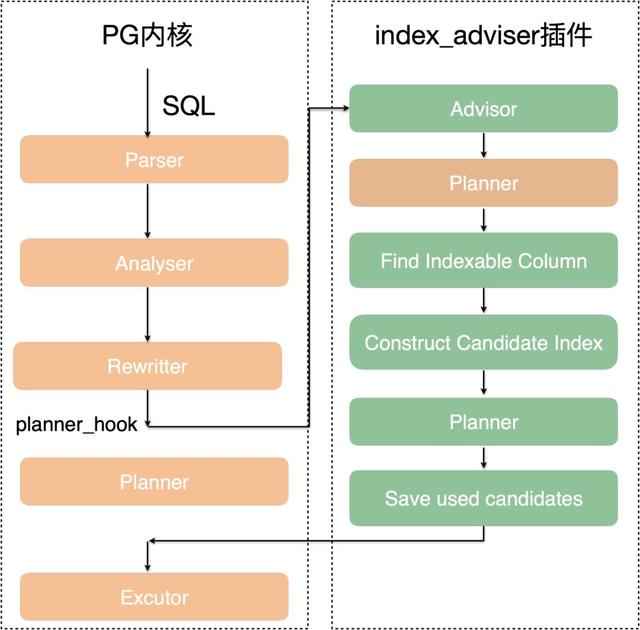

2、智能化索引推荐
采用通用的索引推荐流程,注册planner_hook,遍历查询树,构造索引项,依赖优化器的What-If能力得到结果。

2、详细设计
从查询树到candidate index
针对一条SQL,我们利用内核构造的查询树,精确找到哪些列可以成为索引,制造出索引候选项,交由优化器选择。
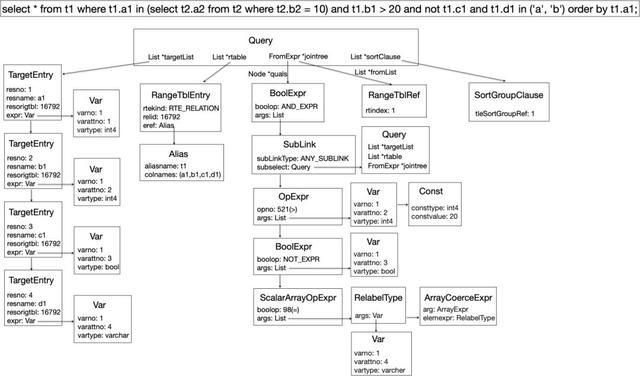
最佳实践
1、从RDS控制台进行可视化操作
进入RDS实例详情页面 -> 自治服务 -> 慢SQL ,可以在此处获得相关操作指引。

2、实操步骤
1、创建表
CREATE TABLE t( a INT, b INT );
INSERT INTO t SELECT s, 99999 - s FROM generate_series(0,99999) AS s;
ANALYZE t;
所生成的表包含以下各行:
a | b
-------+-------
0 | 99999
1 | 99998
2 | 99997
3 | 99996
.
.
.
99997 | 2
99998 | 1
99999 | 02、查询单条SQL建议说明
如果希望索引推荐分析查询并提出索引编制建议但不实际执行查询,将EXPLAIN关键字作为SQL语句的前缀,示例如下:
postgres=# EXPLAIN SELECT * FROM t WHERE a < 10000;
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1693.00 rows=9983 width=8)
Filter: (a < 10000)
Result (cost=0.00..0.00 rows=0 width=0)
One-Time Filter: '** plan (using Index Adviser) **'::text
-> Index Scan using "<1>t_a_idx" on t (cost=0.42..256.52 rows=9983 width=8)
Index Cond: (a < 10000)
(6 rows)postgres=# EXPLAIN SELECT * FROM t WHERE a = 100;
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1693.00 rows=1 width=8)
Filter: (a = 100)
Result (cost=0.00..0.00 rows=0 width=0)
One-Time Filter: '** plan (using Index Adviser) **'::text
-> Index Scan using "<1>t_a_idx" on t (cost=0.42..2.64 rows=1 width=8)
Index Cond: (a = 100)
(6 rows)postgres=# EXPLAIN SELECT * FROM t WHERE b = 10000;
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..1693.00 rows=1 width=8)
Filter: (b = 10000)
Result (cost=0.00..0.00 rows=0 width=0)
One-Time Filter: '** plan (using Index Adviser) **'::text
-> Index Scan using "<1>t_b_idx" on t (cost=0.42..2.64 rows=1 width=8)
Index Cond: (b = 10000)
(6 rows)可通过psql命令行查询index_advisory表内存储的索引编制建议,示例如下:
postgres=# SELECT * FROM index_advisory;
reloid | relname | attrs | benefit | original_cost | new_cost | index_size | backend_pid | timestamp
--------+---------+-------+---------+---------------+----------+------------+-------------+----------------------------------
16438 | t | {1} | 1337.43 | 1693 | 355.575 | 2624 | 79370 | 18-JUN-21 08:55:51.492388 +00:00
16438 | t | {1} | 1684.56 | 1693 | 8.435 | 2624 | 79370 | 18-JUN-21 08:59:00.319336 +00:00
16438 | t | {2} | 1684.56 | 1693 | 8.435 | 2624 | 79370 | 18-JUN-21 08:59:07.814453 +00:00
(3 rows)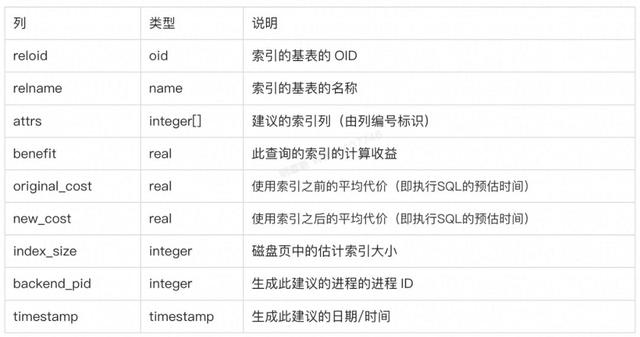
如果语句不带EXPLAIN关键字前缀,索引推荐将在语句执行期间分析语句并记录建议。
3、查询WorkLoad级别建议
通过show_index_advisory()函数获取单个会话的WorkLoad建议,此函数用于获取单个会话的索引推荐(由后端进程ID标识),可通过指定会话的进程ID来调用该函数:
SELECT show_index_advisory( pid );其中,pid 是当前会话的进程 ID。如果不知道当前会话的进程 ID,则传递值 NULL 也将为当前会话返回结果集。
postgres=# SELECT show_index_advisory(null);
show_index_advisory
----------------------------------------------------------------------------------------------------------------------------------------------------
create index idx_t_a on public.t(a);/* size: 2624 KB, benefit: 3021.99, gain: 1.15167301457103, original_cost: 1693, new_cost: 182.005006313324 */
create index idx_t_b on public.t(b);/* size: 2624 KB, benefit: 1684.56, gain: 0.641983590474943, original_cost: 1693, new_cost: 8.4350004196167 */
(2 rows)说明 结果集中每行的表示意义如下:
- 创建索引推荐建议的索引所需的SQL语句。
- 索引页的估计大小。
- 使用索引的总收益(benefit)。
- 使用索引的增益(gain=benefit/size)。
- 使用索引之前的平均代价(即执行SQL的预估时间)。
- 使用索引之后的平均代价(即执行SQL的预估时间)。
通过select_index_advisory视图获取所有会话的WorkLoad建议,此视图包含计算的指标和CREATE INDEX语句,展示当前位于index_advisory表中所有会话的索引编制建议。表t中列a和列b的索引编制建议显示如下:
postgres=# SELECT * FROM select_index_advisory;
backend_pid | show_index_advisory
-------------+----------------------------------------------------------------------------------------------------------------------------------------------------
79370 | create index idx_t_a on public.t(a);/* size: 2624 KB, benefit: 3021.99, gain: 1.15167301457103, original_cost: 1693, new_cost: 182.005006313324 */
79370 | create index idx_t_b on public.t(b);/* size: 2624 KB, benefit: 1684.56, gain: 0.641983590474943, original_cost: 1693, new_cost: 8.4350004196167 */
(2 rows)在每个会话中,从同一建议的索引中受益的所有查询的结果将被组合起来,以便按每个建议的索引生成一组指标,此指标反映在名为benefit和gain的字段中,字段公式如下所示:
size = MAX(index size of all queries)
benefit = SUM(benefit of each query)
gain = SUM(benefit of each query) / MAX(index size of all queries)说明 如果单条SQL建议同时创建多个索引,则index_advisory表中记录的new_cost为创建了多个索引之后的代价,而非创建某一个索引之后的代价。
当对给定会话期间得到的不同建议索引的相对优势进行比较时,gain指标十分有用。gain值越大,从索引中得到的成本效益就越高,这可以抵消索引可能消耗的磁盘空间。
未来展望
阿里云RDS PostgreSQL的索引推荐功能未来还会朝着以下几个方面进行扩展:
- 支持GIN、GIST、BRIN索引的推荐。BRIN索引为block索引,对于无法评估数据分布的场景无法推荐;GIST是数据聚集后的结果,也需要对数据分布有所了解;
- WorkLoad级别的推荐可以更加细化,当前是以benefit做聚合和排序,得出索引推荐,后续可以更加精细化。
作者信息
赵锐,花名:惜元,专注于RDS PostgreSQL内核研发,热爱和分享PostgreSQL数据库相关技术。欢迎有志之士加入RDS产品部!联系邮箱:vogts.wangt@alibaba-inc.com


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/17880.html
相关推荐
-
双活数据中心(同城双活数据中心)
日本天元挑战赛进入第二局的较量,挑战者伊田笃史会不会再次让大家吃惊引人瞩目。 在第一局中,执白的伊田笃史以天元开局,震惊四座。不过那盘棋伊田从一开始就落入下风,没有什么翻盘…
-
万德数据库官网app(万德数据库官网如何查询)
近年来,ESG投资在监管政策“自上而下”地推动下迅速发展。区别于传统投资分析因子,ESG因子能够关注到传统因子分析中未包含的增量信息和投资机会,且ESG投资尚处于萌芽阶段,因子拥挤…
-
本地ip地址(本地ip地址怎么找)
大家好!上期跟大家讲解IP地址的分类,今天就带大家了解下载TCP\IP协议栈中的默认网关, 默认网关和IP地址一样,这个我们就不在重复说了,这个四组的数值取值怎么得来的呢?所谓的网…
-
有线上网(有线上网和无线上网有什么区别呢)
随着科技不断地发展,无线网络从过去的1G到现在的5G,甚至是未来的6G、7G,每一次移动通信技术的更替,都将为社会带来翻天覆地的变化。 从互联网诞生以来,有线网络始终处于“不温不火…
-
小黑卡心悦会员(小黑卡心悦会员有什么用)
?图文均非原创,来源网络侵删致歉 ?小说版权归作者所有 小编只进行片段推文,该小说已完结 ?感兴趣的小伙伴自行搜完整版观看支持作者大大哦 温水煮甜椒 作者:小红柚 文案 注:这是一…
-
上网时间监控软件(上网时间监控软件下载)
随着互联网时代的发展,人们对网络的使用场景日益增加,离开网络可谓是寸步难行,有时就连孩子们的作业都需要手机来完成。为了保护儿童身心健康,预防网络沉迷,和家亲智能组网服务将推出“上网…
-
ons是什么意思啊(ONS是什么意思)
在至暗的时刻也要去追求心中的那束光 在之前那些年,除了委曲求全还有一种无力感,就是对什么事都提不起精神,一切事物都是不受控制的;除了工作照顾女儿,努力工作(职业塑胶模具设计工作,国…
-
网络出现504什么意思(网络异常504是什么意思)_
1.背景本文主要是写得最近比较影响深刻的一次排查客户访问业务前端域名,报504,timeout错误问题的记录,该客户为私有化部署,给客户部署的服务存在跨洲调用,没有专线,澳洲调用欧…
-
异地灾备距离标准(异地灾备距离标准50公里)
数据安全需注意,做好灾备就不慌 在企业IT信息化高度发达的今天,无论是企业还是用户都越来越依赖于IT系统。所以,构建一个业务连续性灾备系统以确保企业运行安全也日益成为各个行业研究的…
-
360云服务器免费(360云服务器免费吗)
哈喽、哈喽,大家好,我是超级Leo。 融媒宝使用快1年了,基本上Leo天天都用来发文章、发视频,减轻了很多日常的工作,同时有些使用的心得也可以分享一下,给各位自媒体用户参考。 1年…