

我们对正则表达式并不感到陌生,平时的工作中一般都会遇到使用它们的场景,即使自己没有用到,在一些插件库或者依赖包里面也经常能看到正则表达式的身影。
vue中的正则表达式
你在平时写代码的过程中使用的多吗?是选择尽量避免使用然后找其它的方式实现,还是直接找一些现成的实现直接拿过来用呢?
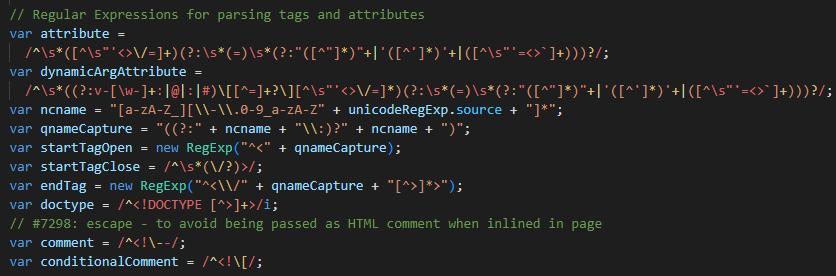
//vue中匹配模板里面插值的正则
var defaultTagRE = /\{\{((?:.|\r?\n)+?)\}\}/g;如果你对正则表达式望而却步,或者对它毫无头绪,不知道自己的需求场景是否适合使用正则表达式,那么我们接下来就去了解一下正则的一些特性,揭开它神秘的面纱,然后再回过头来看上面的例子,就会觉得一目了然,甚至不过如此。

真的嘛?
其实我们只要记住,正则表达式只不过是新的语法书写规则,几乎所有语言都支持正则表达式,js只不过是实现了对它的支持,接下来就让我们走进正则、拥抱正则吧!

让我们开始吧
基础概念
让我们先从一个简单的示例开始,让我们知道正则表达式能做什么。
假设我们有这样一个url地址:
https://www.test.com?id=1&name=tom&_age=18&_sex=1&vip=0我们想要获取查询字符串中的所有数据,并把它们用key、value的形式存储在一个对象中返回,一般情况我们会类似下面这么做:
let url = "https://www.test.com?id=1&name=tom&_age=18&_sex=1&vip=0"
function getQueryVariable(path) {
let query = path.split("?");
if(!query[1]){
return {}
}
let vars = query[1].split("&");
let res = {}
for (var i = 0; i < vars.length; i++) {
var pair = vars[i].split("=");
res[pair[0]] = pair[1]
}
return res;
}
let params = getQueryVariable(url)
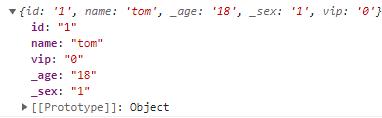
console.log(params)毫无问题,这样我们就可以获取到了结果:
下面我们来用正则表达式做同样的事情(Tips:注意,正则不是用来解决我们用其它方法解决不了的问题,而是简化我们的操作,降低复杂性。换句话说,用正则能解决的问题,那么用其它方法也总是能处理,只是可能复杂性特别高。):
var url = "https://www.test.com?id=1&name=tom&_age=18&_sex=1&vip=0"
function getQueryVariable(path) {
let res = {}
let reg = /[?&]([^=]+)=([^&]+)/g
let mt = null
while(mt = reg.exec(path)) {
res[mt[1]] = mt[2]
}
}
let params = getQueryVariable(url)
console.log(params)我们把函数处理的部分换成了正则的方式,通过查找符合条件的字符串来达到我们的预期:
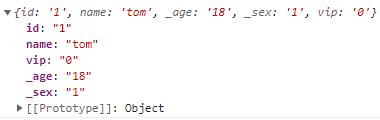
使用正则来处理
先不讨论可读性的问题,我们可以发现,正则表达式其实就是用来检测一个字符串中我们要查找的内容,只不过这个内容是要符合我们指定的规则的。因此正则表达式你可以这么来理解:一个符合某种预定规则的查找机制的表达式。
语法规则
创建一个正则表达式有两种方式:
//构造函数的方式,可以指定第二个参数来约定匹配模式,下面会讲到
let r1 = new RegExp("hello")
//字面量的方式,同样可以在结尾的斜杠后面约定匹配模式
let r2 = /hello/这两种方式构造出来的正则是等价的,只不过实际操作中会有几个不同:
- 构造函数可以传入变量,根据上下文动态生成正则,字面量不可以。
- 构造函数对于特殊字符需要进行转义,而字面量会直接解析。
建议直接使用字面量的形式,会更符合大家的习惯,如果正则是动态生成的,那么只能使用构造函数。
针对第二点,看下面的例子来理解一下:
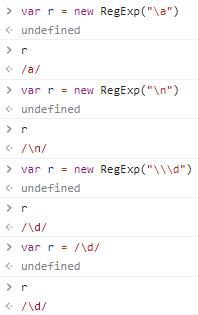
构造函数会进行转义
接下来我们以字面量的形式进行讲解,两个斜杠之间就是我们要描述的内容。
我们可以写任意想要匹配的字符串,如:
let reg = /hello/想要匹配"2022-07-09"中的0就是/0/,匹配2就是/2/,但是如果想要匹配一个字符串中的数字而不关心它是几的时候,该怎么做呢?难道要从0到9十个数字全都写一遍吗?
当然不是,正则表达式中有这样一种特殊的存在,为我们内置提供了一种方式,用\d来表示数字,我们称这个为元字符:
//可以匹配0到9之间的任意一个数字(包括它们自身)
let r = /\d/我们可以把元字符理解为拥有特殊含义的字符组,如"\"和"d"组合在一起就拥有了特殊的功能。
正则里面的元字符非常多,在这里挑几个常用的着重来讲解一下:
"^":匹配字符串的开始位置,如/^o/可以匹配old,但是不能匹配mod,当用在[]中时,表示非的意思,并且是对整体生效,而不是只对第一个字符。如/[^fo]/可以匹配zoo,但是不能匹配foo。
"$":匹配字符串的结束位置。
"|":表示或,如/f|z/可以匹配foo和zoo。
"[]":字符范围,除了使用短横线表示一个范围之外,其他任何字符都是或的关系,如/[a-z]/表示匹配字母a到z之间的任意字符,/[abc]/则与/a|b|c/等价。
"?":表示匹配前面的表达式零次或一次。(*, +, ?, {n}, {n,}, {n,m})这些量词默认使用贪婪匹配,即尽可能多的匹配,当?用在这些量词后面的时候,将开启惰性匹配模式,即尽可能少的匹配。
由于这些元字符要注意的点比较多,并且会产生一些特殊的行为,因此单拿出来说明一下,其他的元字符大家可以自行查阅官方文档。
常用方法
属于正则的有:
test:可以检测一个正则是否能匹配到指定字符串。回返回一个布尔值。
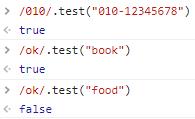
检测是否包含指定字符串
exec:执行匹配,如果匹配成功则返回一个数组,如果开启全局匹配模式,则再次执行会在上次匹配完成的位置继续查找。
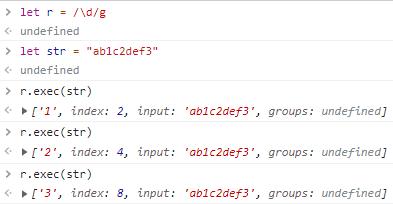
反复查找
(Tips:有一个需要注意的点,每一个字面量都是一个新的对象,因此要赋值给一个变量之后再进行操作,否则每次重新写的正则相互独立会产生非预期的效果。这一点要特别注意,用在while中时,非常容易死循环)
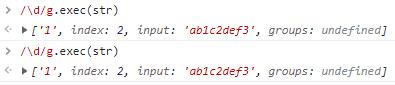
独立的对象
属于字符串的有:
match、matchAll:从字符串中获取给定正则匹配到的内容。
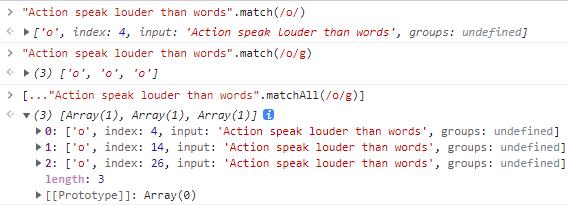
match与matchAll
注意全局匹配修饰符g对于结果的影响,其中matchAll返回的是一个结果迭代器。
replace、replaceAll:替换字符串中匹配到的内容为指定字符串。其中有两点需要注意:
① 第一个参数为正则
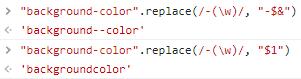
第一个参数是正则
其中$&代表匹配到的字符串,在这里代表"-c",$1代表第一个捕获组,在这里代表"c"。
②第二个参数为函数

第二个参数为函数
其中回调函数的参数遵循以下规则:第一个参数永远为匹配到的字符串,最后一个参数永远为匹配到字符串时的位置,如果有捕获组的话,第二个参数表示第一个捕获组,第三个参数表示第二个捕获组,以此类推,一直到倒数第二个参数。
通过正则和回调函数,灵活性就变得非常高,我们可以做任何想做的事情。
search:查找是否包含指定的匹配。与正则的test不同的是,该方法会返回索引,未找到的话则返回-1。
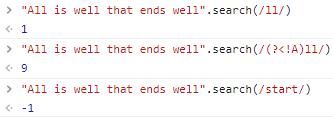
查找给定匹配的位置
split:使用给定匹配对字符串进行分割。
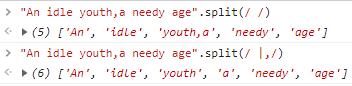
按照给定的规则分割指定字符串
扩展技能
① 重复匹配:
*:表示0次及以上匹配。
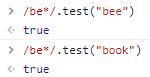
匹配0次或多次
+:表示至少匹配一次。
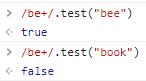
至少匹配一次
{n}:匹配n次。
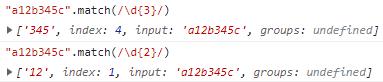
匹配n次
{n,}:匹配n次以及更多。

匹配n次以及更多
{n,m}:至少匹配n次,至多匹配m次。
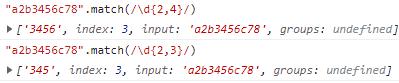
匹配n到m次
?:表示匹配0次或1次。
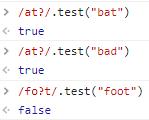
匹配0次或1次
?有一个特殊的地方就在于,如果跟在上面的两次后面的话,会开启惰性匹配模式,而它们默认是贪婪的匹配模式。
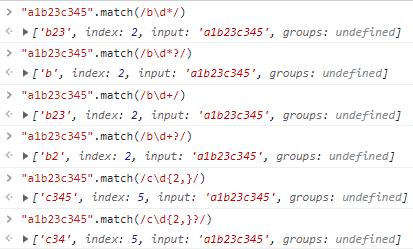
?可以开启惰性匹配
可以看到,当我们使用量词的时候,一般都会尽可能多的获取到符合匹配条件的字符串,也就是贪婪模式。但是如果在后面加上了?,那么就会尽可能少的返回匹配到的字符串,也就是懒惰模式(或称为惰性模式、非贪婪模式)。
② 模式修饰符:
i:忽略大小写,而默认的正则是大小写敏感的。
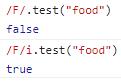
忽略大小写
g:全局匹配,默认是找到匹配的字符串即返回,全部模式会返回所有符合条件的结果。
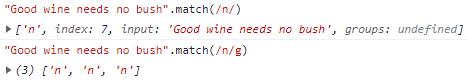
开启全局匹配
u:开启unicode匹配模式,主要用来处理编码大于的字符。
m:多行匹配模式。
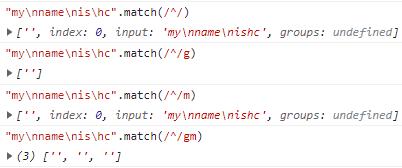
多行匹配
我们匹配字符串中的开始位置,只有开启了全局匹配模式,m修饰符才会生效。
y:粘连修饰符,这个是新增加的,可能比较不好理解,请看例子。
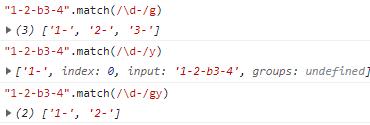
粘连修饰符
我们看到,全局匹配的时候,只要有符合条件的,就会作为结果返回,但是如果用了y修饰符之后,"1-"符合条件返回,立即在这个位置匹配,发现"2-"符合条件,也返回,然后立即在这个位置匹配,发现了b字符,不满足条件,终止匹配。
③ 捕获组:
我们在书写正则表达式的时候,只要被()包裹的部分,就会被作为一个捕获组存在,以便在将来时候,或者在结果中返回。
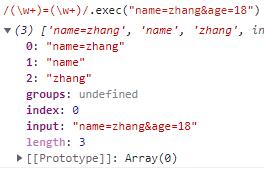
捕获组
返回的结果中,索引1表示第一个捕获组,索引2表示第二个捕获组。捕获组的顺序跟括号出现的顺序保持一致。(a(b(c(d)))),那么abcd表示第一个捕获组,bcd表示第二个捕获组,cd表示第三个捕获组,d表示第四个捕获组。
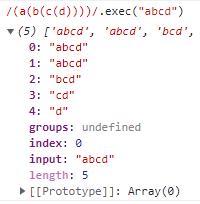
捕获组的顺序
细心的你可能发现了,groups一直都是undefined,那么什么时候它才有值呢?这就涉及到了命名捕获组。使用(?<name>)的模式,其中name为自定义的名字。
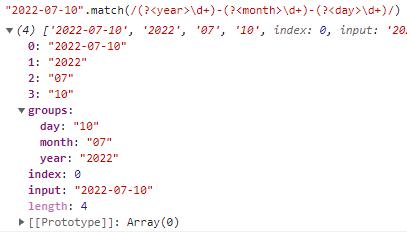
命名捕获组
这样就为我们将来使用获取到的值带来了方便。再看一个例子。
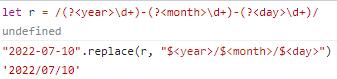
命名引用
(Tips:因为只要使用了括号,就会产生捕获组,如果在必须使用括号的场景下,又不想生成捕获组,那么可以在左括号的后面加上?:,就可以产生一个非获取的匹配。)
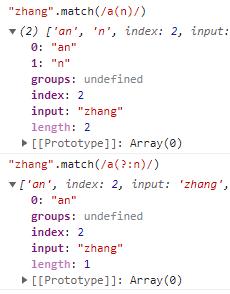
不产生捕获组
④ 反向引用:
这个其实是针对捕获组而言的,当我们在正则里面设定了捕获组,那么我们可以反向引用它。其中\1表示第一个捕获组,\2表示第二个捕获组,以此类推。
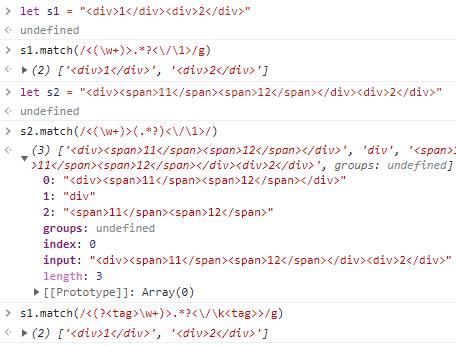
反向引用
可以通过\1引用第一个捕获组,或者可以通过\k<name>引用命名捕获组。
⑤ 预查:表示要匹配的字符串,除了要找到之外,还要满足一定的条件,需要注意的是,预查不消耗字符,可以通过下面的例子来理解一下这些特性。
正向肯定预查:语法格式为a(?=b),表示a的后面需要跟着b,注意这里匹配的是a,也就是后面有b的a。
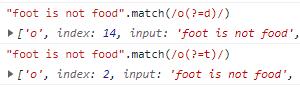
正向肯定预查
正向否定预查:语法格式为a(?!b),表示a的后面不能跟着b,注意这里匹配的是a,也就是后面没有b的a。
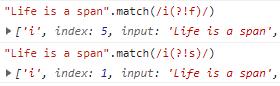
正向否定预查
反向肯定预查:语法格式为(?<=b)a,表示a的前面需要是b,注意这里匹配的是a,也就是前面有b的a。
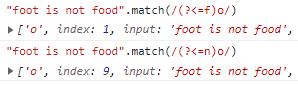
反向肯定预查
反向否定预查:语法格式为(?<!b)a,表示a的前面不能是b,注意这里匹配的是a,也就是前面没有b的a。

反向否定预查
我们再来看一个例子,说明一下为什么预查不消耗字符。我们通过正向肯定预查来看下结果。
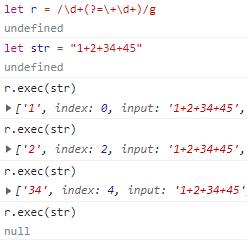
预查不消耗字符
从上面的结果我们很容易就看出来,如果预查消耗字符,那么在第二次执行exec的时候就会匹配到34,而现在的结果是第二次执行返回了2,也就是说第一次预查的时候,没有消耗掉+2字符,而是在第二次匹配的时候从1的后面开始的。

大佬!喝茶!
到这里基本我们已经对正则表达式有了初步的掌握,常用的概念都已经接触到了。来让我们歇息一下,喝杯茶,缓一缓,稍微消化一下刚才的内容。
经典案例
先来一个简单的:
实现一个函数,用正则的方式判断金额是否符合美元格式,如果不是则格式化它。
如$12,345,678 → $12,345,678,$123,456,78 → $12,345,678。
首先构造一个正则,字符串应该以$开始,并且应该以数字结尾,如果前面有逗号的话,那么逗号后面应该有三位数字,所以它可能长这样:
let r = /^\$\d{1,3}(,\d{3})*$/看下结果:
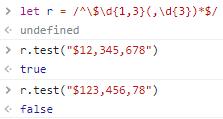
验证是否合法
接下来如果不是的话,我们要重新组合这串数字,让它符合美元格式。
所以我们的思路是重新组合这些数字:
//获取到所有数字,结果返回一个数组
let res = "$123,456,78".match(/\d/g)
//重新拼成字符串
let str = "$" + res.join("")然后使用捕获组来进行匹配,将得到的捕获组进行替换,先从后面往前数,每三个为一组,我们使用正向肯定预查,如12345678,我们从后面开始找出三个数是678,然后继续查找是345,最后剩下的数字就是最前面的数字12,那么表达式匹配到的就是后面跟着345678的12,把12替换成"12,",然后再对345678重复上面的步骤,所以我们需要一个全局匹配,看起来像下面这样:
str.replace(/(\d{1,3})(?=(\d{3})+$)/g,'$1,')所以最后的函数看起来可能是这个样子的:
function testMoney(money) {
let r = /^\$\d{1,3}(,\d{3})*$/
if(r.test(money)) {
return money
}
let res = money.match(/\d/g)
let str = "$" + res.join("")
let formate = /(\d{1,3})(?=(\d{3})+$)/g
return str.replace(formate,'$1,')
}来验证一下是否可行呢?
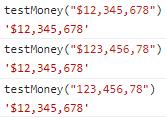
格式化金额
测试通过。
再来个复杂的:
让我们想象一下这样一个场景,在注册的时候,为了保证密码的高强度性,一般需要校验密码是否符合规则:必须至少包含数字、小写字母、大写字母中的两种,并且长度不能少于8位,不能多于16位。
如mypassword → false,myPassword → true,mypassword1 → true
首先我们从题目中得知,至少包含两种字符,那么可以分析出是一种小写字母要跟着数字或者小写字母跟着大写字母等等的情况,就会想到使用预查的方式。
//表示需要有数字
let r1 = /^(?=.*\d)/
//表示需要有小写字母
let r2 = /^(?=.*[a-z])/
//表示需要有大写字母
let r3 = /^(?=.*[A-Z])/
//组合起来表示有数字和小写字母,由于有.*的存在,所以不分顺序
let r4 = /^(?=.*\d)(?=.*[a-z])/
//组合起来表示有数字和大写字母,由于有.*的存在,所以不分顺序
let r5 = /^(?=.*\d)(?=.*[A-Z])/
//组合起来表示有小写字母和大写字母,由于有.*的存在,所以不分顺序
let r6 = /^(?=.*[a-z])(?=.*[A-Z])/我们通过预查,得到了两两组合的情况,已经保证了有两种字符的要求,由于三种字符也是满足题目的,所以后面可以随便跟随一种字符,也就是两两组合之后,再随便跟一种字符,然后按照此规则重复规定的次数即可。
//所有情况组合起来
let r = /^(((?=.*\d)(?=.*[a-z]))|((?=.*\d)(?=.*[A-Z]))|((?=.*[a-z])(?=.*[A-Z])))[0-9a-zA-Z]{8,16}$/这样我们就得到了至少两种字符组成的密码检验,来看一下检测结果:(Tips:一定要注意正则表达式之中不要随便添加空格,因为空格也会被解析成匹配的一部分!)
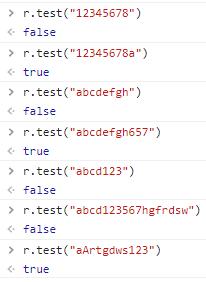
密码校验
测试的几种情况全部通过。
问题思考
最后给大家留几道关于正则的题目,可以尝试着解一下,看看是否能给出满足条件的答案呢?
- 针对上面的格式化金额的题目,如果存在小数点的时候,该怎么处理呢?
- 校验密码的题目中是否还有更简单的写法来表达呢?
- 找出一个字符串中,所有出现重复的连字符串,如abbcdefffgh中的bb和fff。
- 在3的基础上,找出重复的字符串组,如abcbcdefgefgh中的bc和efg。
- 实现一个函数,利用正则匹配,解析一个层级深度大于等于2的DOM树结构。

感谢阅读!


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/14923.html
相关推荐
-
月租云主机(月租云电脑)
认识家庭云电脑 01-什么是家庭云电脑? 家庭云电脑 依托中国电信优质云网资源及先进桌面虚拟技术,通过app形式把云端电脑集成到机顶盒及移动终端中,提供和PC一样的配置(包括vCP…
-
亿恩科技有限公司(亿恩科技是做什么的)
虎符缠臂,佳节又端午。端午节是我国传统节日之一,而粽子作为端午节的特色食品,寓意人们安康美好。为了更好地弘扬和传承端午节的文化内涵,体现企业人文关怀,增强员工幸福感和凝聚力,202…
-
云存储空间占用手机内存吗(云存储空间是什么)
云空间,计算机科学术语,是大容量云空间集合,由多台服务器提供负载均衡,资源网站实际按需要进行动态分配,适合网站比较多或者是网站建设公司,比VPS性能强,价格更便宜。 云空间具有独立…
-
国际轻量服怎么解决服务器维护(国际服服务器维护中怎么解决)
互联网时代,无论是个人还是企业,都在使用服务器。在使用服务器的过程中,可能大家都会遇到这样那样的问题,服务器虽然出现故障的情况比较少,但也不是百分百的不会出现。服务器故障出现之后,…
-
阿里云ecs服务器(阿里云ECS服务器价格)
为了更好地满足企业日益加深的大规模使用服务网格产品、服务多语言互通、服务精细治理等需求,2022 年 4 月 1 日起,阿里云服务网格产品 ASM 正式发布商业化版本,为企业在生产…
-
轻量服务器可以生成备案授权码吗(备案授权码怎么用)
??上一篇文章主要讲解了WordPress主题的设置,距离完成一个完整的个人网站搭建还差最后一步。 因为我们购买的一般是国内的服务器,所以要实现域名与IP地址的解析,备案就是必须要…
-
云服务器搭建梯子教程(用云服务器搭建梯子)
NextCloud是什么 Nextcloud是一款开源免费的私有云存储网盘项目,可以让你快速便捷地搭建一套属于自己或团队的云同步网盘,从而实现跨平台跨设备文件同步、共享、版本控制、…
-
域名服务提供商怎么写(域名服务提供商有哪些)
网络安全事件的警示 网络对手已经超越了攻击操作系统和应用程序,而是将恶意代码嵌入硬件本身。 实现硬件信任根的零信任框架可以阻止对硅、固件和其他基本系统组件的攻击。 企业需要采购依赖…
-
美国vps推荐(VPS 美国)
#奇妙知识季#?#头号周刊#?#人人能科普,处处有新知#? 史崔克装甲运兵车没有主动装甲美国陆军恢复寻找主动防御系统,以装备史崔克家族装甲车辆。这个项目始于十年中期,然后测试了几个…
-
轻量应用服务器mc服务器(MC服务器大全)
上先结论吧,网易官方即是裁判,又是游戏参与者,极其不公平的对待第三方服务器,我的界服务器生态迟早药丸。 先看看大家看到的: 你说这种程度的推广密度,你让第三方服务器怎么 活?怎么和…
