
导读:全文将围绕以下三点展开:
- 年度回顾
- 泛日志场景机会与挑战
- Elasticsearch日志Serverless服务1.0
01
年度回顾
1. Elasticsearch(简称ES)发展进程
①2018年:Elasticsearch上云
- 兼容开源版本,开箱即用
- 多集群运管效率提升
②2019年:ELK生态组件全托管
- Elasticsearch5.5/6.3/6.7/7.4云上多版本发布
- Beats/Logstash/Kibana云上全托管服务
③2020年:APack引擎通用增强
- 计算存储分离架构
- 索引压缩插件
- 时序查询剪枝
- 物理复制插件
- Faster-bulk
④2021年:日志增强版
- IndexingService:写入Serverless服务
- 智能海量存储引擎1.0:存储Serverless服务
- Elasticsearch TSDB时序引擎(与社区共建)
⑤2022年:日志Serverless服务
- APack2.0日志执行引擎
- 智能海量存储引擎2.0:智能冷热存储
- 云原生数据采集
2.发展阶段
在2020年以前,Elasticsearch主要是进行产品通用能力的建设:
- ES产品功能丰富,适用场景广泛,客户分布在多个甚至十多个集群,通用增强能给客户提供更好的体验,比如配置管理、监控报警、插件管理等。
- ES生态组件丰富,希望客户能得到一站式体验,从而降低使用成本。
- 在不影响客户兼容性的情况下,增强ES引擎的能力,因此通过插件中心发布查询分析、稳定性增强、写入优化、监控报警等二十多个插件。
通过以上三方面工作,从管控、生态、内核三方面全面增强阿里云ES产品能力,解决ES企业级客户上云提效的需求。
2020年以后,随着上云客户对降低成本的需求,ES重点针对日志场景提供日志增强版,集成Indexing Service和智能海量存储引擎子产品解决日志场景需求。
—
02
泛日志场景机会与挑战
企业数字化转型过程中,大量企业通过Elasticsearch满足日志检索、存储、归档审计的需求。
1. 泛日志场景的挑战
随着企业数字化转型和互联网企业对数据安全的关注,泛日志数据管理需求愈发重要,如云原生服务及系统日志、安全审计、互联网企业的用户型分析等;同时ELK生态全观察功能也越来越丰富和完善,更多企业选择ELK开源生态来解决业务需求。
泛日志场景的挑战主要有以下三个方面:
①高写入吞吐和弹性
- 千万级写入:客户将ES用于泛日志场景,首先解决的是数据接入问题,而日志场景经常是写多读少,很多客户的日志写入量都非常大,达到TB级以上,因此提供高吞吐写入是ES首先要解决的问题。
- 快速扩展能力:此外还存在写入突增和峰谷差异大问题,比如由于扩容不及时造成写入拒绝。
- 稳定性保障:为保障线上服务的稳定性,需要相对专业的ES引擎支持,和对内部机制的理解。
②海量日志存储成本
包括长周期日志存储、数据冷热特点明显、归档存储需求等。
泛日志数据是典型的带时间属性的数据,数据规模会随着时间逐步累积,因此大中型客户的存储规模非常大,给SRE人员增加了额外的运维成本。
③分析性能瓶颈
如Ad-hoc查询、统计分析需求、多租户查询等。
泛日志场景查询通常是对数据进行多维度统计分析,这类查询的资源控制和性能会产生问题。
2. 阿里云Elasticsearch产品解决方案-日志增强版
针对上述挑战,阿里云ES推出日志增强版,在产品架构上引入了三个组件:Indexing Service、智能海量存储引擎和APack。
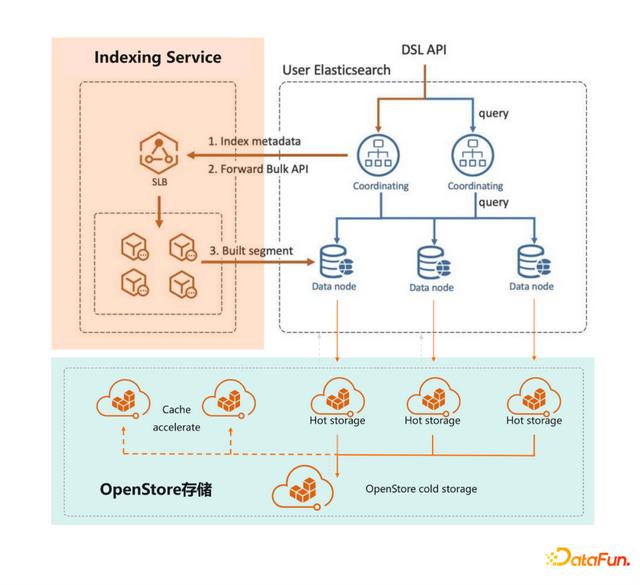

ES日志增强版产品架构
①Indexing Service
读写分离架构,一个超大的ES集群阵列,专做Indexing Build,每个客户可灵活使用。
- 高性能写入:ES内核层优化将单位资源写入性能提升了150%,并通过“削峰填谷”的云原生特性为客户在单位时间内保留海量算力。
- 物理复制:通过segment级的实时物理复制,平均数据延迟在百毫秒级内。
- 异地容灾高可用:异地多活架构,服务本身的高可用性。
②智能海量存储引擎
低成本索引存储,服务化多级存储及索引调度能力,无需关注存储介质。
- 高查询性能:多级存储及cache优化,用更低的费用获得更优的IOPS。
- 计算存储分离:存算资源完全解耦,提升索引迁移及恢复的速度,集群扩展性有效提升。
- 全自动索引生命周期管理:基于简单的索引周期配置,智能化托管索引生命周期调度的全过程。
- 异地容灾高可用:异地多活架构,存储服务本身的高可用性保障。
③Apack,内核定制优化
—
03
Elasticsearch日志Serverless服务1.0
2022年,阿里云将ES日志增强版升级为日志Serverless服务产品,并正式发布日志Serverless服务1.0。
1. 日志Serverless服务1.0的核心价值
日志Severless服务1.0的核心价值是:性价比、高吞吐和易运维。
- 高吞吐:云端写入10倍能力提升,解决时序日志数据高并发写入瓶颈。
- 性价比:成本降低70%,优化集群计算/存储资源成本,提供按需使用,按实际流量/存储空间付费。
- 易运维:云原生Serverless,降低大规模集群运维复杂度,支持秒级弹性伸缩和全托管式免运维服务。
2. 内核技术架构
在ES日志增强版技术架构中,最下层是云原生管控服务平台,上面是Indexing Service、智能海量存储引擎和APack。

ES日志增强版技术架构图
①云原生管控服务平台:解决资源管理、多租户调度、安全审计、企业级监控报警和智能诊断等问题,以提升客户产品运维体验。目前关注的问题主要是变更效率,包括:可灰度、可监控和可回滚三个核心问题。
②Indexing Service索引构建服务:主要解决高吞吐和弹性问题,通过读写分离架构,将Indexing Service作为独立服务,同时通过存算分离,独立Indexing Service所需资源,用户只需关注写入吞吐,按实际使用量付费。平台的两个主要工作:
- 第一,通过物理和逻辑隔离,实现海量客户的多注入构建平台。
- 第二,流式索引管理和资源管理,为客户提供按需扩容和按量付费的云原生Serverless能力。
- 另外,还集成了内核增强特性,针对阿里云的内核定制优化,以提升写入索引构建性能。
③自研海量存储引擎:针对存储成本的思考,从冷数据存储出发,引入存算分离架构,冷存集成支持阿里云OSS对象存储,查询性能通过索引格式调优,多级Cache缓存和混合储存。
④APack执行引擎:主要针对多租户查询Serverless服务,实现细密度查询租户控制和资源隔离,降低SRE集群管理难度和成本;另外根据智能海量存储引擎产品特性和日志查询特点,定制预读和剪枝策略,以提升查询性能。
3. 服务特性
①高性价比日志存储引擎
- 读写分离架构:快速弹性伸缩 + 降低资源冗余
- 存算分离架构:基于OSS降低冷数据存储成本
- 索引压缩:ZSTD压缩、日志场景配置调优等
- 性能优化:针对日志场景写入和查询分别定制优化
②开箱即用的Serverless服务
- 独立索引构建服务:免运维、按写入吞吐量付费
- 定制索引存储服务:
- a. 用户可按需购买:降低冗余的存储成本
- b. 智能冷热分离:降低用户区分冷热的运维成本
- 云原生管控服务:提升用户服务变更体验和效率
阿里云ES团队积极参与社区建设,与Elasticsearch社区和国内团队紧密合作,基于Elasticsearch在云原生的实践,推出了包括开发者报告、Elasticsearch全观测、技术解析等电子书,对ES感兴趣的朋友可以多多关注。同时,在ES社区也会有丰富的线上线下活动,欢迎大家参与。

今天的分享就到这里,谢谢大家。
阅读更多技术干货文章、下载讲师PPT,请关注微信公众号“DataFunSummit”。
分享嘉宾:邓万禧 阿里巴巴 资深技术专家
出品平台:DataFunTalk
01/分享嘉宾

02/报名看直播 免费领PPT

03/关于我们
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章700+,百万+阅读,14万+精准粉丝。
欢迎转载分享,转载请私信留言。


使用无须实名的阿里云国际版,添加 微信:ksuyun 备注:快速云!
如若转载,请注明出处:https://www.hanjifoods.com/13479.html
相关推荐
-
云计算的含义是什么(云计算的含义简单而又短的一句话)
#人人能科普,处处有新知#云计算是指使用托管在Internet上的远程服务器网络来存储、管理和处理数据,而不是使用本地服务器或个人计算机。 云计算允许企业将其计算需求转移到这些远程…
-
买东西的软件有哪些(有没有帮买东西的软件)
每一个孩子都是小天使。她们都曾趴在云朵上,认认真真地挑选妈妈,她们选中了你,来到你的身边,全心全意的陪伴你,爱着你! 能被女儿选中成为她的妈妈是件多么幸福的事!小小的她一心一意地爱…
-
google官网登录账号(google官网登录入口)
最近的报告显示,谷歌正在向数量极少部分用户测试其桌面上的搜索主页的全新布局。这个 “新Google.com “与传统的主页相去甚远,是一块干净的页面。除了搜索栏和不断变化的涂鸦谷歌…
-
亚马逊新品打造爆款全流程解析(5000字干货长文)t种子链接(亚马逊新品打造爆款全流程解析(5000字干货长文))
大家好,点击右上方“关注”,不定期分享亚马逊运营知识和干货。 今天给大家分享亚马逊新品如何打造爆款链接,内容很长也很干,大家一定要耐心看完。 01测款试款 做亚马逊的老铁都知道,七…
-
哦哦哦哦哦哦哦是什么歌(喔哦哦哦哦哦哦哦哦哦是什么歌)
这些天来,部分深圳市民们迎来了“幸福的烦恼”,天天被鸟儿吵醒。 事实上,每个地方的早晨都能听到鸟叫声,我们通常并不觉得烦躁,但是惊扰深圳市民的并不是普通的鸟儿,而是叫声非常凄惨的“…
-
leapftp下载,leapftp下载的文件打不开
市场上充斥着各种各样让人眼花缭乱的下载器,都有自己的特色,但或多或少也有自己的弊端,今天为大家推荐两款我自己用了两年多的手机端下载器。 一个是ADM,一个是1DM+。这两款下载器有…
-
金斗云智投汇正财经app(金斗云智投是正规平台吗)
在众多不同类型企业办公软件当中,现在精斗云标准版软件 可以说是脱颖而出,得到广大企业认可,主要原因就是版本非常先进,性能特别稳定,使用功能很完善。方便企业在工作管理中操作,带来安全…
-
美国虚拟空间年费(美国虚拟空间租用)
编辑导语:伴随着元宇宙概念的火热,VR产业似乎也迎来了爆发。然而从供需端来看,VR产业的消费端明显疲弱,那么要从哪儿抄手VR,胜算才更大呢?一起来看一下吧。 今年五一没法儿旅游好想…
-
东营做网站推广(东营做网站的公司)
大众网·海报新闻见习记者 朱钰琪 郭军晓 东营报道 任志强作为“广饶信息网”的创始人,为给广饶人民提供一个方便快捷的本地信息服务平台,自2010年创立网站至今,经过13年的不懈努力…
-
云电脑是什么意思(远程云电脑是什么)
离开办公室,云电脑真的能提升工作效率么?并不能。云电脑是为用户提供云端专属电脑的服务,虽然有取代传统电脑的趋势,但从本质上仍然是一台电脑。因此,我们能奢求一台电脑督促我们工作么?我…